As a bit of background, initially I was just going to do all the querying from within BigQuery. But it was a bit clunky, and kind of intimately tied me in to the process of getting the data the supervisors wanted. My manager pointed out that a more general solution was probably preferable, so I looked into getting the .csv data into a SQL database. This is the rest of the story...
Setting up the Azure SQL Database
There really isn't that much to setting up a SQL Server database in Azure. The portal has apparently been updated (cause, that doesn't happen all the time </sacasm>. SQL databased -> Add ... configure, save. The one thing that nipped me, not a huge deal, was that I created a new server, and forgot to set the firewall rule. So just remember to do that. The one other bit of info we'll want is the connection string. I had trouble connecting using the server address and my credentials, so I ended up using the ADO.NET connection string instead.
 |
| Probably doesn't even bear mentioning... |
 |
| Don't forget your filewall rules on the server... |
 |
| Don't know if the breadcrumbs were always there, but I like... |
Now for the annoying part...
In my mind, reading from a .csv file should be a solved problem. I won't minimize the difficulty of taking that parsed data and dropping it in a database schema, but come on... a parser should be able to handle quoted commas and newlines, right? Not the Import data tool. I spent way too much time on the sad path, dicking around with opening my files in Notepad++ and Sublime Text looking for anything that could trip up the import tool. This was frustrated further by the flat nature of the data... there were a ton of columns, and I had to stretch the editors across all three of my monitors to get it down to single lines. Ok, rant over, but just keep in mind that the .csv parsing in this tool isn't terribly robust.
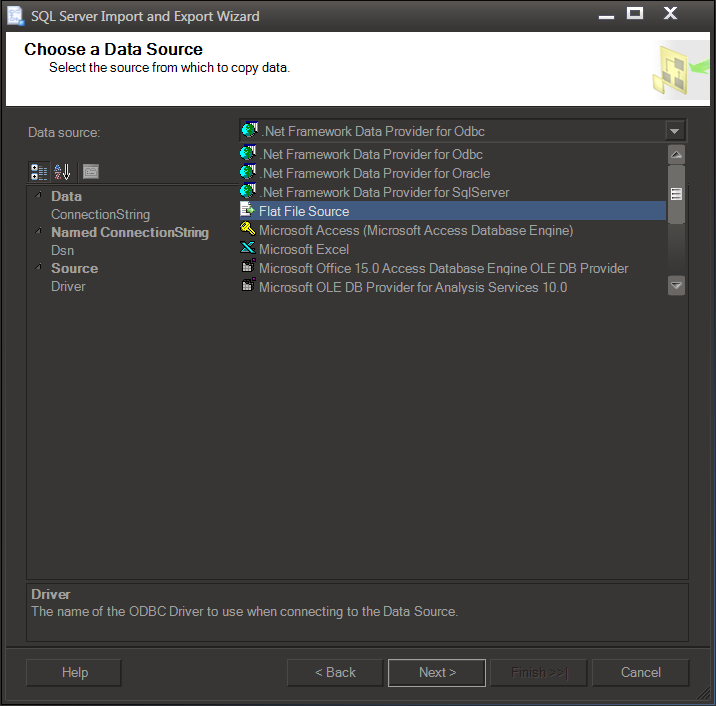
For our .csv files, we're going to select "Flat File Source" on the Data Source screen. The files are created with just "\n" line endings (not "\r\n"), so we have to configure the right line endings, or it will complain about "I read xxx Kb of data and didn't see a line ending, should I keep scanning?". There is a bit on the "General" screen about header line endings, however this is not going to fix what it uses to end each row. For that, we have to go to "Columns" and change it there. It confused me initially and I ran through the whole process a couple times before I realized it was screwed up...
 |
| Oops, line endings are no good... |


Next we configure the destination. Remember those connection strings? Here is where we copy-paste it in. Select ".Net Framework Data Provider for SqlServer". I tried using the Native Client (which is what the instructions I found online said to do) and couldn't get it to work, so I said f*ck it and switched the provider. You'll need to substitute your password into the connection string text, once you blur the field it will hide the password. It also seems to populate the other fields in the form based on the connection string, so you could probably use those directly, but I didn't try it, so ymmv. If you do it wrong, it'll tell you about it.


Next is the "Select Source Tables and Views" screen. You can change the name of the target table here, but what I think is the important thing here is the "Edit Mappings" option, which will let us customize how data types are converted. For .csv files, strings (meaning everything) default to varchar(50), whereas from Excel they default to nvarchar(255). Excel will also default numeric data to floats it seems. Here I have some Unix millisecond time stamps mapped to bigint, and the human readable version mapped to datetime. Further down I have some calculated values mapped to floats.

The following screen warns us that a bunch of fields may be truncated. We need to set On Error and On Truncation to "Ignore" here, or it'll never work because pretty much everything is going to think it's being truncated. If there is a real problem, it'll fail anyway (as we shall see...) dun dun duuuuun!

For our purposes, we're good to go and can skip the rest of it. If this were to evolve into a normal thing I might see if there was an advantage to saving a package.

 |
| Yay, it working!... |
 |
| ... oh hell, nevermind =( |
So, I got so sick of seeing these damn error messages with this particular file. I hunted down every quoted comma and newline, edited the query in BigQuery generating the file (you can see the query on my previous post), re-exported the file so I could try again. I must have generated this stupid file at least twenty times. Eventually I decided enough was enough... I was trying something else. I was able to get away with loading it into Excel because it was only about 70,000 rows. So I loaded the .csv into Excel, changed nothing, and saved it as an .xlsx file.
The process for migrating an Excel file in this way is almost identical as described above. Instead of a "Flat File Source", we pick Microsoft Excel. When I picked the file, it automatically changed the Excel Version (.xls is also supported).

With an Excel source (probably other sources as well), we can run a query on the source data prior to uploading it. Handy, but not necessary for my purposes. Moving on...


Ah, success. So satisfying after so much heartache and frustration. Opening up the Azure database in SSMS, we can see both the failed .csv table (_TEST) and the successful Excel migration (_EXCEL). A row count reveals the failed migration left out about 7000 rows.

I was able to get another .csv file to load (the HTSASSIGNMENTS_EXPORT table seen above). It had a much simpler schema with fewer opportunities for wonky input, so it didn't give me any trouble. Well that's all I got. I hope this was helpful to you and good luck in your migration efforts.
[UPDATE]
I managed to automate the process with Jenkins. I wrote it up here.
[UPDATE]
I managed to automate the process with Jenkins. I wrote it up here.
No comments:
Post a Comment