Handwavy, tl;dr version:
- Back up entities to Cloud Storage
- Import into BigQuery
- Export .csv
- Migrate with SQL Server Import - Export Data tool
Our help ticket system at work (creatively named "HTS") is hosted on Google AppEngine, with data persisted to the HR datastore. My manager approached me (since I'm the "appengine developer") and asked me if it would be possible to do a "data dump". Nothing pretty, just get it all out and into a spreadsheet or something so that supervisors could run some rudimentary reporting (the build-in capabilities in HTS weren't cutting it). So I rolled up my sleeves and got to work. Here's how it all went down...
So the first question I had was "Is this even possible to get the data out?". I assumed the answer was yes, but how? A bit of Googling revealed that it is
possible to backup the datastore entities from the Datastore Admin screen into Google Cloud Storage. The document on backups mentioned exporting entities to BigQuery (since they weren't in a form I could use directly and I didn't know about the bulkloader), and the
docs on BigQuery explained how data could be imported from Cloud Storage. The data could then be
exported from BigQuery as a .csv file. So, the first big hurdle seemed to have a clear path.
Now, I'd never run a datastore backup before, and this was a production system, so I was a bit leary about just going in there will-nilly and pushing buttons. Fortunately, there were a couple test systems for HTS that had similarly large numbers of entities, so I tried out the process on them first:
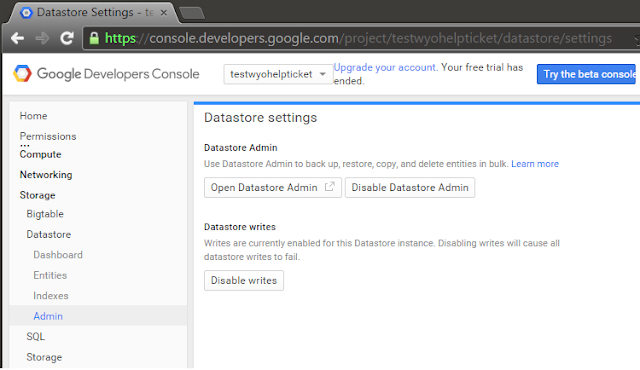 |
| Find the datastore admin... |
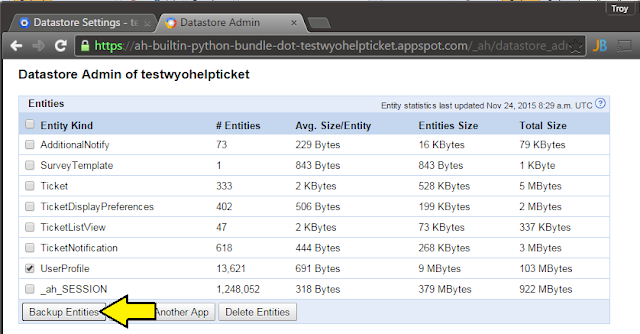 |
| ... select entities to back up... |
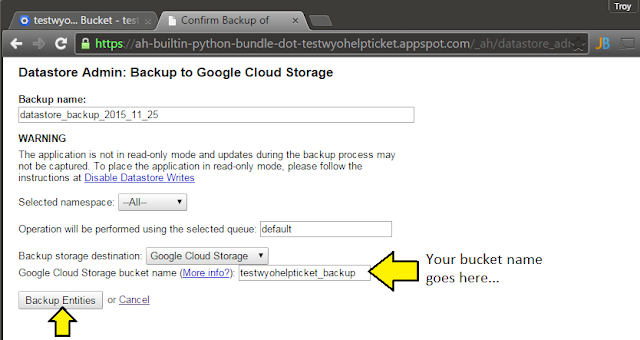 |
| ... select the GCS bucket ... |
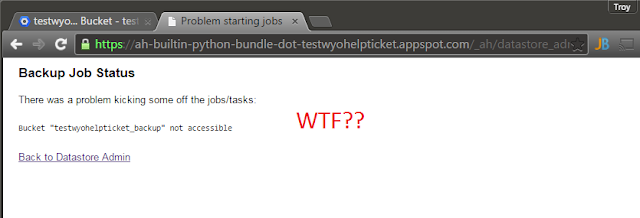 |
| ... aaaaaaand fail. |
Not accessible? Did I not grab the right name, do I need all the gs:// jazz? ... I spent a fair bit of time flailing about trying to figure out what the hell when wrong, when finally StackOverflow pointed me in the right direction. Turns out I needed to add a permission to allow the service account access. For Pete's sake...
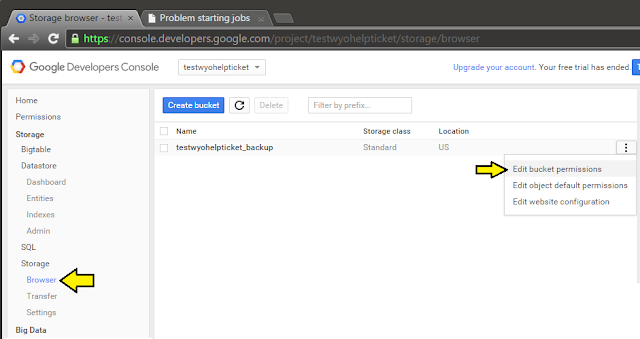 |
| Go to Storage -> Browser, and click the settings menu on the far right... |
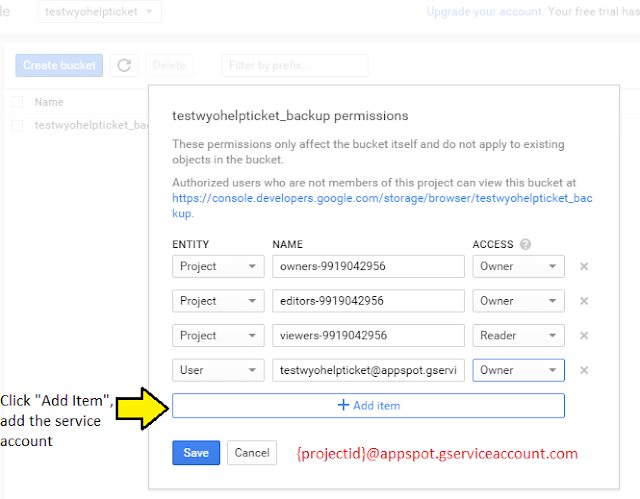 |
| ... add the service account (Writer probably would have worked...)... |
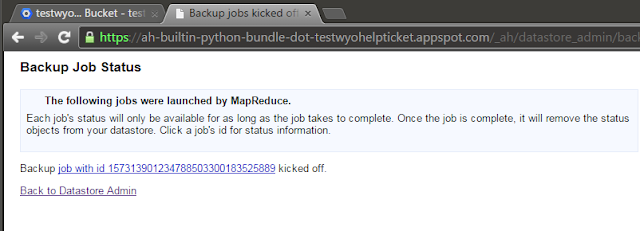 |
| Try backup again and get the happy path... |
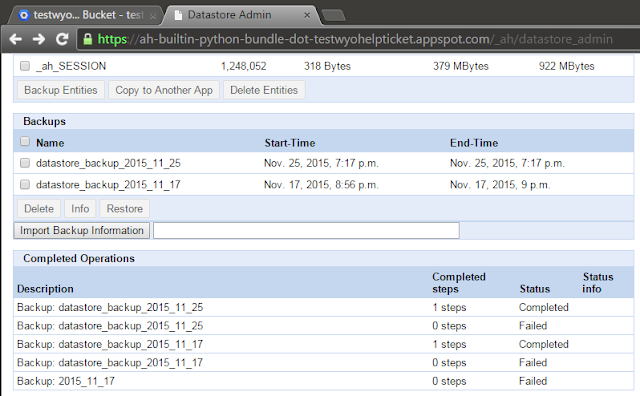 |
| ...our backup is that top item in "Completed Operations" |
Onward to BigQuery
So, now that I have the data backed up to GCS, loading it into BigQuery should be easy... right? It is, once you know what you are doing. Navigate to BigQuery (it's under "BigData" in the Dev Console). The first time I did this I had to enable it through the API's menu.
 |
| Select BigQuery API, hit the big blue "Enable" button. |
Once in BigQuery, you'll need to create a dataset (I have the "DarkReader" extension turned on, so my BigQuery is very dark):
For our purposes I created two datasets, called Import_Data and Export_Data. Our backed up datastore entities will go into Import, and the cleaned up data will go into Export (I didn't do it that way originally, but having done a few, it would have been more clear). Now the really fun part: Import the data into a table. When you hover over the dataset, a + will appear on the right, click it to add a table:
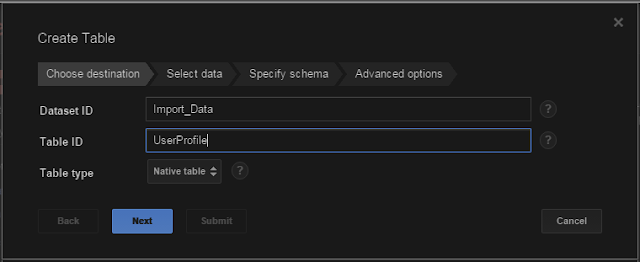 |
| Pick a table name... |
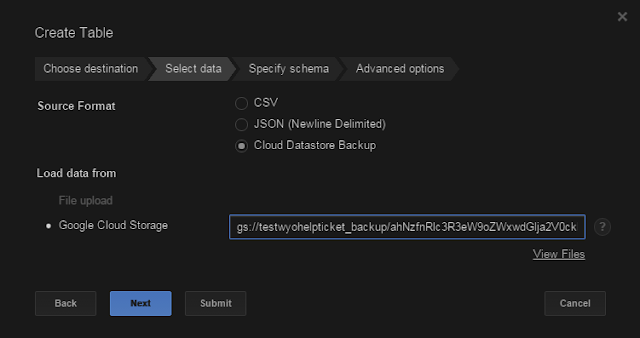 |
... point it to the right file in Cloud Storage...
...oh, where'd that come from, you ask?... |
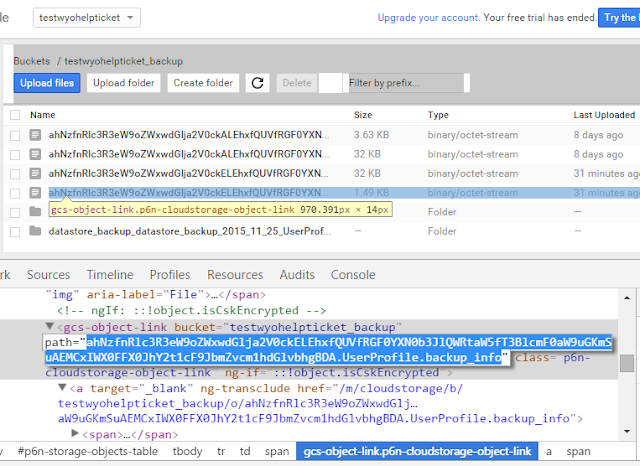 |
... see those files with long incomprehensible names?
It's one of those... good luck... |
 |
| Assuming you found the right file, you should see this. |
I really struggled with figuring out the URL for the "Load data" portion. Let's back up a step (no pun intended). When we ran the backup of the datastore, it created some metadata files, one for each kind, and one for the overall backup. The file we are interested ends with .{kind}.backup_info. This fact is mentioned in the docs, but what it fails to mention is that the first part of the filename is 118 characters long, preventing the suffixes from showing up in the web ui. Thanks for that, Google, seriously... So you either have to zoom waaaaaaay out, or "inspect elements" on the links. But once you get the right filename, the storage url looks like gs://{bucket_name}/{ridiculous_filename}.
Now that we are all loaded up, we can run some queries. Clicking the table (under the dataset) will open up metadata about the columns. Click "Query Table" to open up a new query with a basic skeleton, or "Compose Query" for a completely new query. Clicking fields in the metadata window will automatically insert them under the cursor in the query editor, which is pretty handy:
The query is automatically validated, and can be saved for future reuse. Once we have a result set, if it's small it can be downloaded directly, but usually it has to be saved as a table and exported to GCS:
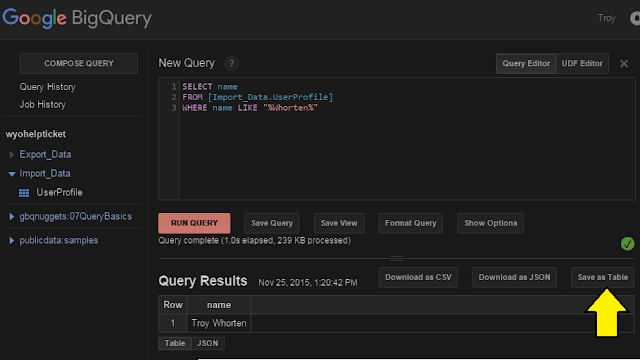 |
| One row we could download directly, but usually we'll "Save as Table"... |
I exported this to a table called "UserProfile_Export" in the "Export_Data" dataset. If you float over the table and click the down arrow on the right, select "Export Data" and the export data window will come up:
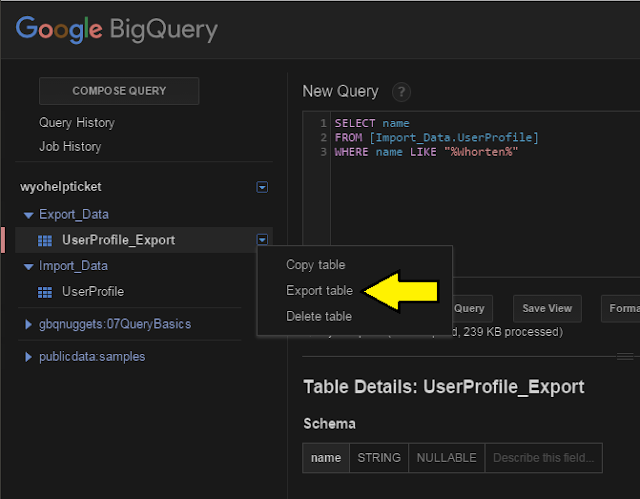 |
| Dataset -> Table -> Export table... |
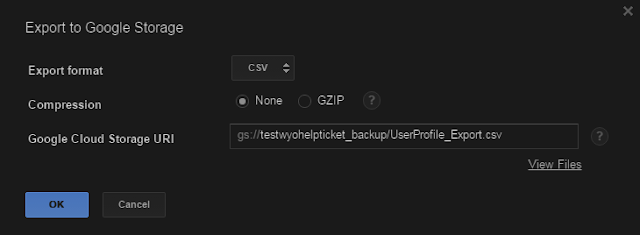 |
| ... point it at your bucket and give it a good filename. Easy peasy. |
If you decide to gzip the exported table, do youself a favor and name the file with a .gz extension, cause BigQuery won't do it for you. It puts it in
exactly the file you specify. Once it's in GCS, just browse to the file, click, and download. Congrats, you now have your datastore entities in csv format. One note: there are a number of caveats and gotchas when querying with BigQuery (it's pretty close to SQL but not exactly). Like you can't have two repeated fields in the same query, and there is no DISTINCT (you have to use GROUP BY). Also, depending on your data migration tool, you may have to do some clean up. The
query docs were invaluable, and really have some good functionality. My BIGBAD table gave me a huge headache, I ended up doing a bunch of stuff to clean it up and STILL had to load it into Excel and import it as an .xlsx file... smh.
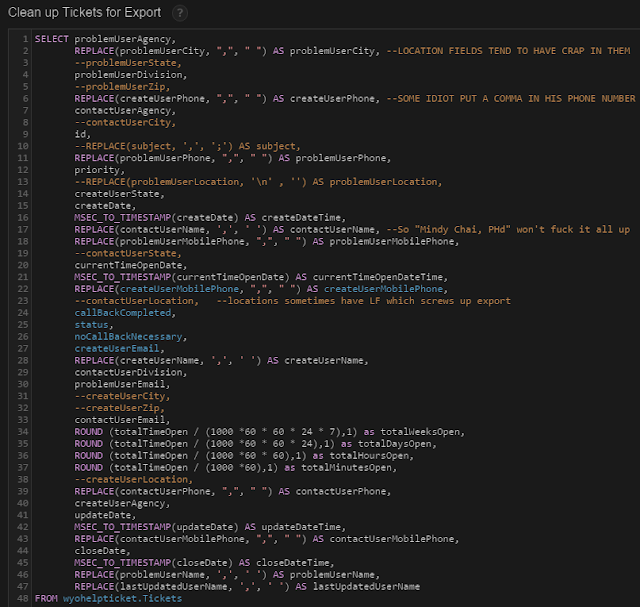 |
| A lot of annoying trial and error went into the creation of this query... |
In the next post, I'll cover using the SQL Server 2014 Import - Export Data tool to load our .csv file into Azure...


















I follow the same steps but end up in getting a response does not contain valid backup metadata. (error code: invalid).
ReplyDeleteHow far in the process did you get before it bombed out?
DeleteIt worked! I was missing out the 'kind' name which had to be inserted before .backup_info. Currently the UI for storage and bigquery are different than the one you have shown(URI didn't contain the kind name which I got from datastore admin backup info or by inspecting storage file).
ReplyDeleteAwesome! Glad you got it working. Honestly it's been so long since I put this all together, I'm not surprised that some of the UIs are different.
DeleteThanks for the post.
ReplyDeleteYou're welcome =)
Delete