Exam Objectives
Define HTTP resources with HTTP actions; plan appropriate URI space, and map URI space using routing; choose appropriate HTTP method (get, put, post, delete) to meet requirements; choose appropriate format (Web API formats) for responses to meet requirements; plan when to make HTTP actions asynchronous; design and implement routesQuick Overview of Training Materials
Exam Ref 70-487 - Chapter 4.1
[Blog] Using HTTP Methods (GET, POST, PUT, etc.) in Web API
[Apigee] Web API Design: Crafting Interfaces that Developers Love
[HackerNoon] RESTful API Designing guidelines — The best practices
[MSDN] Web API Routing
[Blog] Using HTTP Methods (GET, POST, PUT, etc.) in Web API
[Apigee] Web API Design: Crafting Interfaces that Developers Love
[HackerNoon] RESTful API Designing guidelines — The best practices
[MSDN] Web API Routing
[MSDN] Media Formatters in ASP.NET Web API 2
[MSDN] REST URI Support in Web API - Converting UriTemplates to Routes
[PluralSight] Implementing an API in ASP.NET Web API
[Blog] ASP.NET MVC and Web API - Comparison of Async / Sync Actions
[MSDN] REST URI Support in Web API - Converting UriTemplates to Routes
[PluralSight] Implementing an API in ASP.NET Web API
[Blog] ASP.NET MVC and Web API - Comparison of Async / Sync Actions
Before one can really understand what Web API is built to do, you need to have a basic understanding of REST. I'm skeptical that there is a lot of value into going deep in the weeds on REST and it's history, so I'll link to the Wikipedia page and you can go down that rabbit hole if you are curious [follow the white rabbit].
The important thing to understand about REST is that it aims to take full advantage of the HTTP protocol to build intuitive, stateless APIs. Entities (either singular or collections) are addressed in the URI, and HTTP verbs (GET, POST, PUT, PATCH, DELETE, among others) are used to perform typical CRUD actions against these entities.
The Apigee whitepaper is an excellent starting point to understand REST and API design in a technology neutral way (i.e. it is not Web API specific). Our URI typically address the nouns that we care about; these are our resources. If I'm building a dog management api, I would represents a collection of dogs as http://api.mydomain.com/dogs. If I want to list all the dogs, I call this URI with a GET request. To create a new dog, I might use a POST request with a JSON or XML representation of a dog in the body. If I include an identifier for a specific dog in the URI, I can use other operations. GET would retrieve that single dog, perhaps with more detailed data, PUT and PATCH would be used for an update (full or partial, respectively), and DELETE would remove the dog.
With this basic understanding of what REST basically is, the facilities built into Web API map very cleanly to the REST concepts, making it easy to build RESTful APIs.
Define HTTP resources with HTTP actions
Like ASP.NET MVC, Web API has the notion of a controller. Controllers are usually (but not necessarily) associated with a single resource. So continuing with our DogApi example, we would have a controller for Dog called DogController that would inherit from ApiController (or a subclass, like if we have a custom base class). It is important to note that ApiController comes from the System.Web.Http namespace, in contrast to the MVC Controller class, which comes from System.Web.Mvc.
The barebones Web API controller template (the read/write action one, not the empty one) includes Actions that are named to match HTTP verbs: 2 "GET" methods (one returning a collection, and one taking an id and returning a single result), "POST" and "PUT" methods that take in a request body as a string, and a "DELETE" method that also takes an id. By convention, WebAPI will match incoming requests to methods that start with the verb, so "Get()" and "GetDogs()" would both be a match to a GET request with no parameters.
In addition to these actions, you can define additional methods that will also be accessible to consumers of the API. However, as you add more methods to the controller, you need to think carefully about the way these methods are resolved by Web API. If we create the following method, as is, on our controller:
then issuing a GET request to /api/Dogs will throw an error, because now WebAPI has two methods that map to the GET request with no parameters:

But if we just change the name of the method to "PostSomethingElse", the error goes away because WebAPI is no longer matching the method on GET requests. Alternatively, we can also control which method responds to a request by changing the method signature. If we add two parameters to the GetSomethingElse method like so:
The barebones Web API controller template (the read/write action one, not the empty one) includes Actions that are named to match HTTP verbs: 2 "GET" methods (one returning a collection, and one taking an id and returning a single result), "POST" and "PUT" methods that take in a request body as a string, and a "DELETE" method that also takes an id. By convention, WebAPI will match incoming requests to methods that start with the verb, so "Get()" and "GetDogs()" would both be a match to a GET request with no parameters.
using System; using System.Collections.Generic; using System.Linq; using System.Net; using System.Net.Http; using System.Web.Http; namespace DogApi.Controllers { public class DogsController : ApiController { // GET: api/Dogs public IEnumerable<string> Get() { return new string[] { "value1", "value2" }; } // GET: api/Dogs/5 public string Get(int id) { return "value"; } // POST: api/Dogs public void Post([FromBody]string value) { } // PUT: api/Dogs/5 public void Put(int id, [FromBody]string value) { } // DELETE: api/Dogs/5 public void Delete(int id) { } } }
In addition to these actions, you can define additional methods that will also be accessible to consumers of the API. However, as you add more methods to the controller, you need to think carefully about the way these methods are resolved by Web API. If we create the following method, as is, on our controller:
public string GetSomethingElse() { return "Something Else"; }
then issuing a GET request to /api/Dogs will throw an error, because now WebAPI has two methods that map to the GET request with no parameters:
But if we just change the name of the method to "PostSomethingElse", the error goes away because WebAPI is no longer matching the method on GET requests. Alternatively, we can also control which method responds to a request by changing the method signature. If we add two parameters to the GetSomethingElse method like so:
public string GetSomethingElse(string a, string b) { return "You passed in " + a + " and " + b; }
then the "Get()" method will work as expected (return two values), and when we pass in "a" and "b" in the query string, we'll hit the "GetSomethingElse" method:

Plan URI space and map it to routes
While the example above shows the beginnings of what our DogApi URIs will look like, real applications will have considerably more complexity. In particular, most data models include complex associations between entities... our DogApi might include owners, supplies, veterinarians, breeders, etc. that are all connected in complex relational graphs.
The Web API Design whitepaper and the Best Practices article make some well reasoned arguments for following certain design practices. The first, which I've seen pretty much everywhere that describes REST API design, is that URL's should include only the "nouns", that is, the resouces, and not the verbs. The verbs are taken care of by the HTTP verbs used to access the URL describing a given resource or collection of resources.
Another point that both documents agree on is that resource names in the URL should be plural. This is more readable and consistent, since a resource without an identifier generally represents a collection. Consider our DogApi example:
/api/Dogs - returns an IEnumerable
/api/Dogs/1 - returns the dog resource with ID = 1
The whitepaper suggests keeping resource URL's as short as possible, where most should not have to extend beyond the pattern /{resource}/{identifier}/{resource}. The "Best Practices" article adds one more layer of {identifier} to specify a specific associated resource. This could prove useful in cases where doing a POST or DELETE on a subresource removes the association rather than the actual resource. So if I had a collection of dog toys, I might get the list of all of them at:
/api/Toys
Whereas I would get the toys for Dog #1 with a subresource:
/api/Dogs/1/Toys
The Web API Design whitepaper and the Best Practices article make some well reasoned arguments for following certain design practices. The first, which I've seen pretty much everywhere that describes REST API design, is that URL's should include only the "nouns", that is, the resouces, and not the verbs. The verbs are taken care of by the HTTP verbs used to access the URL describing a given resource or collection of resources.
Another point that both documents agree on is that resource names in the URL should be plural. This is more readable and consistent, since a resource without an identifier generally represents a collection. Consider our DogApi example:
/api/Dogs - returns an IEnumerable
/api/Dogs/1 - returns the dog resource with ID = 1
The whitepaper suggests keeping resource URL's as short as possible, where most should not have to extend beyond the pattern /{resource}/{identifier}/{resource}. The "Best Practices" article adds one more layer of {identifier} to specify a specific associated resource. This could prove useful in cases where doing a POST or DELETE on a subresource removes the association rather than the actual resource. So if I had a collection of dog toys, I might get the list of all of them at:
/api/Toys
Whereas I would get the toys for Dog #1 with a subresource:
/api/Dogs/1/Toys
Taking the toy away from Dog #1 would entail issuing a DELETE to the toy's identifier in the subcollection:
DELETE /api/Dogs/1/Toys/0
While throwing the toy away completely would mean deleting it from the base resource:
DELETE /api/Toys/0
This is but one approach to relationships. Another approach is to treat associations as a first class resource (discussed by a couple answers to this StackOverflow question). This is somewhat analogous to a join table in a SQL database, where resource A can have many B's, and resource B can have many A's (thinks students and classes).
Beyond just getting a collection of resources, we may want to sort, filter, and page the results we get back from collections. The design whitepaper advocates for "sweeping complexity behind the ?", that is, using query string parameters to handle these functions. Our URLs in these cases would look something like these:
If we have 10 dogs per page, and zero based page numbers, we'd get dogs 40-49:
/api/Dogs?page=3
If we only want dogs named "Fido", we'd filter on that attribute:
/api/Dogs?name=Fido
If we want to control the attribute to sort on, and the sort direction (say, sort on "name" in ascending order):
/api/Dogs?sortBy=name&sortDir=asc
Alternatively, the HackerNoon article presents another approach to sorting. We might have multiple "sort" params that each capture the attribute and direction. We want to sort on "name" in ascending order, from heaviest to lightest weight:
/api/Dogs?sort=name_asc&sort=weight_desc
Finally, we might want to allow for "search" or "query" capabilities, which would get a separate parameter:
/api/Dogs?search=Fido
Backing up a little bit, one of the other points made by the whitepaper, and sort of implicitly touched on in the PluralSight course, is the idea of choosing the right level of abstraction when mapping out your URL space. Say our "Dogs" API was part of a larger "Pets" API. One way to approach this would be to add a layer to the url:
/api/Pets/Dogs
Then if we wanted to add APIs for Birds, Cats, and Fish, they would all live under the "Pets" umbrella. On the other hand, if we were worried that this could lead to an explosion of subcategories (and the associated increase in supporting code), we could make "species" a property of a more abstract "Pet" entity and just lump everything together. The whitepaper suggests keeping the number of concrete resources (Dogs, Cats, etc.) in the one to two dozen range.
I'll get into the details of routing below. The way the routes map onto the URL space are going to be pretty intuitive. I made this breakdown to quickly map out what we've basically covered above:

This would break down into at least two routes, one with the template "api/Pets/Dogs/{id}" with id as an optional parameter (to allow for both the base collection at api/Pets/Dogs and the specific data on Dog #1 at api/Pets/Dogs/) and another with the template "api/Pets/Dogs/{id}/Friends/{friendId}" with id required and friendId optional. But I'll get into the nitty gritty on routes when I discuss implementation.
Choose appropriate HTTP verb
The correspondence of HTTP verbs to CRUD actions is generally pretty straight forward, but there are some nuances, particularly around side effects and idempotency. The GET operation should be side effect free; when you execute a GET, you get the information but you don't change anything. When you are creating a new resource, POST is generally considered the correct method, and it is not idempotent... that is, multiple calls will create duplicate records. PUT is generally considered idempotent (being something of a "upsert" operation, either updating an existing resource or creating a new one). PATCH is considered a "partial update" method and apparently is not idempotent, and the spec for PATCH offers another rabbit hole for the curious. The base HTTP spec details GET, POST, PUT, and DELETE.
There are multiple mechanisms by which you can control the way controller actions are selected in response to different HTTP verbs. The most common verbs are mapped to method name conventions, GetThis and PostThat, etc. This is fine as long as a given method is only responding to a single verb. If you need the same method to respond to multiple HTTP verbs, you can use annotations. There are two ways you can do this annotation: the [Http*] annotations, and the [AcceptVerb()] annotation.
There are seven Http* annotations (as of this writing): HttpGet, HttpPost, HttpPut, HttpPatch, HttpOptions, HttpHead, and HttpDelete. These are the attributes from the System.Web.Http namespace, not the nearly identical ones from System.Web.Mvc. These attributes are stackable, so if you want a method to respond to GET and POST the same way, just add the [HttpGet] and [HttpPost] attributes above the method. If you want a method to respond to many verbs, or verbs besides those listed above, you can use the [AcceptVerbs()] annotation. Simply pass in one or more strings corresponding to the verbs you want to respond to. These can be esoteric verbs (like some of the ones I saw in PostMan and Fiddler), or even completely custom verbs. I created a simple test method that responds to everything:
I was then able to test it in PostMan and Fiddler:


While these attributes give you a great deal of flexibility, they are probably largely an academic curiosity with respect to a well designed restful API. The vast majority of the time, the standard basic verbs, GET, POST, PUT, PATCH, and DELETE will suffice. While it's interesting that we can configure actions to respond to obscure non-standard or even custom HTTP verbs, putting this into production would make our interface much harder for third parties to use and would probably lead to lots of snickering and/or head scratching by the poor schmucks who have to consume the API...
There are multiple mechanisms by which you can control the way controller actions are selected in response to different HTTP verbs. The most common verbs are mapped to method name conventions, GetThis and PostThat, etc. This is fine as long as a given method is only responding to a single verb. If you need the same method to respond to multiple HTTP verbs, you can use annotations. There are two ways you can do this annotation: the [Http*] annotations, and the [AcceptVerb()] annotation.
There are seven Http* annotations (as of this writing): HttpGet, HttpPost, HttpPut, HttpPatch, HttpOptions, HttpHead, and HttpDelete. These are the attributes from the System.Web.Http namespace, not the nearly identical ones from System.Web.Mvc. These attributes are stackable, so if you want a method to respond to GET and POST the same way, just add the [HttpGet] and [HttpPost] attributes above the method. If you want a method to respond to many verbs, or verbs besides those listed above, you can use the [AcceptVerbs()] annotation. Simply pass in one or more strings corresponding to the verbs you want to respond to. These can be esoteric verbs (like some of the ones I saw in PostMan and Fiddler), or even completely custom verbs. I created a simple test method that responds to everything:
[HttpGet] [HttpPost] [HttpPut] [HttpPatch] [HttpOptions] [HttpHead] [HttpDelete] [AcceptVerbs("LINK", "UNLINK", "COPY", "PURGE", "LOCK","UNLOCK","PROPFIND","VIEW","CUSTOM")] public string Action() { return Request.Method.ToString(); }
I was then able to test it in PostMan and Fiddler:


While these attributes give you a great deal of flexibility, they are probably largely an academic curiosity with respect to a well designed restful API. The vast majority of the time, the standard basic verbs, GET, POST, PUT, PATCH, and DELETE will suffice. While it's interesting that we can configure actions to respond to obscure non-standard or even custom HTTP verbs, putting this into production would make our interface much harder for third parties to use and would probably lead to lots of snickering and/or head scratching by the poor schmucks who have to consume the API...
Choose appropriate format
Out of the box, WebAPI supports several formats for serialization: JSON, XML, BSON (Binary JSON), and form encoded. Additional media types can be supported through the use of MediaFormatters. The format(s) a client wants to receive is specified in the "Accept" header of the request. While the documentation indicates that when a media formatter cannot be found for the requested format, WebAPI is supposed to return a 406 status (Not Acceptable)... it seemed to just return JSON for me all the time. Maybe I'm not doing it right.
The documentation presents an example creating a CSV file, I thought I would keep it even simpler and create a formatter for our Dog API that returns a really basic string representation. This is the complete formatter:
The only other step is to add the formatter to the config with the line
config.Formatters.Add(new DogMediaFormatter());
The documentation presents an example creating a CSV file, I thought I would keep it even simpler and create a formatter for our Dog API that returns a really basic string representation. This is the complete formatter:
public class DogMediaFormatter : BufferedMediaTypeFormatter { public DogMediaFormatter() { SupportedMediaTypes.Add(new MediaTypeHeaderValue("application/Dog")); } public override bool CanReadType(Type type) { return false; } public override bool CanWriteType(Type type) { if (type == typeof(Dog)) { return true; } else { Type enumerableType = typeof(IEnumerable<Dog>); return enumerableType.IsAssignableFrom(type); } } public override void WriteToStream(Type type, object value, Stream writeStream, HttpContent content) { using (var writer = new StreamWriter(writeStream)) { var dogs = value as IEnumerable<Dog>; if (dogs != null) { foreach (var dog in dogs) { WriteItem(dog, writer); } } else { var singleProduct = value as Dog; if (singleProduct == null) { throw new InvalidOperationException("Cannot serialize type"); } WriteItem(singleProduct, writer); } } } private void WriteItem(Dog dog, StreamWriter writer) { writer.WriteLine("[Dog] name = {0}, owner = {1}, toy count = {2}, friend count = {3}", dog.name, dog.owner.name, dog.toys.Count, dog.friends.Count); } }
The only other step is to add the formatter to the config with the line
config.Formatters.Add(new DogMediaFormatter());
Set the "Accept" header to "application/Dog" and voila:
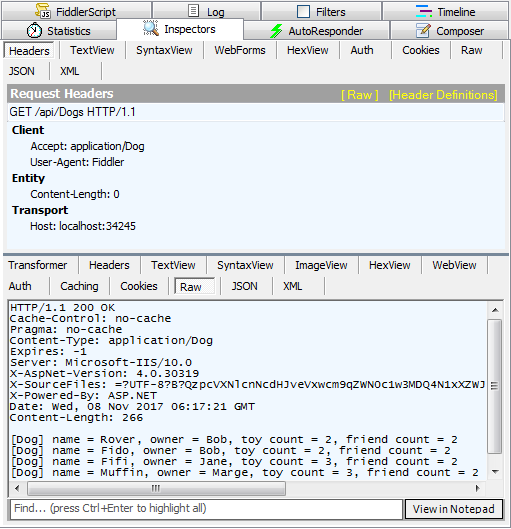
Plan when to make actions asynchronous
The Exam Ref makes the assertion that the determining factor for when to make an action asynchronous is whether the action is CPU bound or I/O bound. This makes sense, as the idea behind async programming is to free the thread to do other work while it's waiting for something to finish (like an I/O call). If the thread is never really waiting for anything because all it does is work, there is nothing to be gained by giving the thread to another request.
The blog post by Gökhan Şengün comparing synchronous with asynchronous methods comes to the same conclusion, but actually does the math and then backs the assertion up with some experimental data. I thought about tweaking the IIS Express thread pool and running a similar experiment, but I would have to monkey around with the IIS Express config (can't seem to change it form web.config), which just wasn't worth the hassle [EDIT I tried anyway based on this and this but still got nothing interesting...]. I did create two barebones actions demonstrating the two styles:
If "SomeSlowMethod" is CPU intensive, then we would expect these two methods to perform about the same, and there would be no advantage to using the asynchronous style. If, on the other hand, it was some I/O bound process like fetching data from disk or the web, then the async style would make much more efficient use of resources (much better throughput). This can be a difference maker in high traffic scenarios.
The blog post by Gökhan Şengün comparing synchronous with asynchronous methods comes to the same conclusion, but actually does the math and then backs the assertion up with some experimental data. I thought about tweaking the IIS Express thread pool and running a similar experiment, but I would have to monkey around with the IIS Express config (can't seem to change it form web.config), which just wasn't worth the hassle [EDIT I tried anyway based on this and this but still got nothing interesting...]. I did create two barebones actions demonstrating the two styles:
[HttpGet] public async Task<string> AsyncAction(string p) { return await Task.FromResult(SomeSlowMethod()); } [HttpGet] public string SyncAction(string p, string a) { return SomeSlowMethod(); }
If "SomeSlowMethod" is CPU intensive, then we would expect these two methods to perform about the same, and there would be no advantage to using the asynchronous style. If, on the other hand, it was some I/O bound process like fetching data from disk or the web, then the async style would make much more efficient use of resources (much better throughput). This can be a difference maker in high traffic scenarios.
Design and Implement routes
A good complement to the Apigee whitepaper, which gives great guidance on designing resource URI schemes, is the PluralSight course on Web API, which demonstrates pragmatic ways of handling routing. Most of the principles behind designing routes I think were covered above in the discussion of designing the URL space, so I'll focus here on actually creating the routes.
WebAPI routes are very similar to MVC routes (again, just watch the namespaces). Routes can be created two ways: attribute routing using the [Route()] and [RoutePrefix()] attributes, and defining the routes using the MapHttpRoute() config method.
Attribute routes were introduced with WebAPI 2, and allow you to create routes directly on the controller class and action methods. If all the methods on the controller share a common prefix, this prefix can be specified using the [RoutePrefix("prefix")] attribute. The prefix can be overridden by using the ~ to start the route specified in the [Route()] attribute. Methods that are not annotated with [Route] may still be picked up by the routes configured directly in WebApiConfig.
One their own, these [Route] attributes don't actually fully implement the routes. For the routes to be registered with WebAPI, you need to call MapHttpAttributeRoutes() on the HttpConfiguration object. The default template does this already in the WebApiConfig.cs file, right before it defines the default route.
Both attribute routes and convention based routes support making parameters optional and setting constraints on parameters. In the above example, "id" is optional. The following snippet demonstrates how to add default values and constraints to a convention based route:
We can see that some of the values being given defaults ("controller") or a constraint ("httpMethod") don't appear as template parameters. The {alpha} parameter gets a default value of "alpha", and also must meet the constraint (specified as a regex) that it be only alpha characters. The same can be accomplished with the [Route] attribute:
The constraints built into Route actually provide more robust options, such as type checking for int, alpha, bool, and datetimes, as well as checking value constraints (min, max, etc.). Default values can be specified either in the route or in the method signature (as above). The documentation for attribute routing goes into depth on the constraints available.
WebAPI routes are very similar to MVC routes (again, just watch the namespaces). Routes can be created two ways: attribute routing using the [Route()] and [RoutePrefix()] attributes, and defining the routes using the MapHttpRoute() config method.
Attribute routes were introduced with WebAPI 2, and allow you to create routes directly on the controller class and action methods. If all the methods on the controller share a common prefix, this prefix can be specified using the [RoutePrefix("prefix")] attribute. The prefix can be overridden by using the ~ to start the route specified in the [Route()] attribute. Methods that are not annotated with [Route] may still be picked up by the routes configured directly in WebApiConfig.
[RoutePrefix("api/Verbs")] public class VerbsController : ApiController { [HttpGet] // GET /api/Verbs [Route("")] public string Action() { return Request.Method.ToString(); } [HttpGet] // GET /api/Verbs/async [Route("async")] public async Task<string> AsyncAction() { return await Task.FromResult(SomeSlowMethod() + "_async"); } [HttpGet] // GET /api/sync [Route("~/api/sync")] public string SyncAction() { return SomeSlowMethod(); } ...
One their own, these [Route] attributes don't actually fully implement the routes. For the routes to be registered with WebAPI, you need to call MapHttpAttributeRoutes() on the HttpConfiguration object. The default template does this already in the WebApiConfig.cs file, right before it defines the default route.
// Web API routes config.MapHttpAttributeRoutes(); config.Routes.MapHttpRoute( name: "DefaultApi", routeTemplate: "api/{controller}/{id}", defaults: new { id = RouteParameter.Optional } );
Both attribute routes and convention based routes support making parameters optional and setting constraints on parameters. In the above example, "id" is optional. The following snippet demonstrates how to add default values and constraints to a convention based route:
config.Routes.MapHttpRoute( name: "ConstrainedApi", routeTemplate: "api/Constraints/{alpha}/{id}", defaults: new { controller = "Constraints", id = RouteParameter.Optional, alpha = "alpha" }, constraints: new { alpha = @"[A-Za-z]+" , httpMethod = new HttpMethodConstraint(HttpMethod.Get) } );
We can see that some of the values being given defaults ("controller") or a constraint ("httpMethod") don't appear as template parameters. The {alpha} parameter gets a default value of "alpha", and also must meet the constraint (specified as a regex) that it be only alpha characters. The same can be accomplished with the [Route] attribute:
[HttpGet] [Route("api/Constraints/v2/{alpha:alpha}/{id:int?}")] public string GetConstrainedValueV2(string alpha, int id = 0) { return alpha + " | " + id + "... version 2.0"; }
The constraints built into Route actually provide more robust options, such as type checking for int, alpha, bool, and datetimes, as well as checking value constraints (min, max, etc.). Default values can be specified either in the route or in the method signature (as above). The documentation for attribute routing goes into depth on the constraints available.
No comments:
Post a Comment