Exam Objectives
Access data storage in Azure; choose data storage mechanism in Azure (blobs, tables, queues, SQL Database); distribute data by using the Content delivery network (CDN); handle exceptions by using retries (SQL Database); manage Azure CachingQuick Overview of Training Materials
Exam Ref 70-487 - Chapter 1.4
[PluralSight] Windows Azure Storage In-Depth
[MSDN] Introduction to Microsoft Azure Storage (complete docs)
[MSDN] Storage Queues vs Service Bus Queues
[MSDN] Azure SQL Database Documentation
[MSDN] Azure Redis Cache FAQ
[MSDN] Azure Redis Videos
[MSDN] Azure Storage Client Library Retry Policy Recommendations
[MSDN] Transient fault handling
[MSDN] Retry Guidance for Specific Services
[MSDN] Overview of Azure CDN
[MSDN] What is the Azure SQL Database service?
[MSDN] Microsoft Azure Table Storage - Not Your Father's Database
[MSDN] Azure Storage Table Design Guide
[MSDN] Using Azure PowerShell with Azure Storage
[Channel9] Windows Azure Tables and Queues Deep Dive
[PluralSight] Windows Azure Storage In-Depth
[MSDN] Introduction to Microsoft Azure Storage (complete docs)
[MSDN] Storage Queues vs Service Bus Queues
[MSDN] Azure SQL Database Documentation
[MSDN] Azure Redis Cache FAQ
[MSDN] Azure Redis Videos
[MSDN] Azure Storage Client Library Retry Policy Recommendations
[MSDN] Transient fault handling
[MSDN] Retry Guidance for Specific Services
[MSDN] Overview of Azure CDN
[MSDN] What is the Azure SQL Database service?
[MSDN] Microsoft Azure Table Storage - Not Your Father's Database
[MSDN] Azure Storage Table Design Guide
[MSDN] Using Azure PowerShell with Azure Storage
[Channel9] Windows Azure Tables and Queues Deep Dive
Data Storage Options In Azure
I talked a little bit about the data storage options available in Azure in my post on choosing data access technology, but it's really a course grained, high level overview. Easily the best resource I found for learning the insides and out of Blobs, Tables, and Storage Queues, was the Azure Storage In Depth PluralSight course. It was very thorough (almost 7 hours), covered some real world scenarios for using queues, tables, and blobs, management and monitoring... good stuff.
Because I did a rough overview in the data access post, and I'll get into depth on actual usage below, here I'll just quickly summarize each of the covered technologies:
Because I did a rough overview in the data access post, and I'll get into depth on actual usage below, here I'll just quickly summarize each of the covered technologies:
- Azure Storage Accounts
- Blobs - unstructured text and binary data
- Tables - NoSQL datastore, semi-structured
- [Storage] Queues - FIFO-ish queue (not to be confused with Service Bus Queue)
- File - Network share in the cloud with SMB access
- Disk - Virtual drive for a VM
- Azure Redis Caching - Replaces old In-Role and Managed Cache services
- Azure CDN - Content Delivery Network services provided by Verizon and Akumai
- Azure SQL - SQL Server in the cloud, with some caveats.
While at first blush many of these technologies seem to have a clear niche, it is not always so easy to choose one over the other:
File Backup Scenario: Say we want to cheaply back up a bunch of files. The two mechanisms we might look at are Blobs and Files, each with their own strengths (StackOverflow's take). Blobs are roughly 30% or less the cost of Files per GB, and can store much greater total data per container. However, if SMB access is important, or maybe you have files that are bigger than 200GB (limit on a block blob), and you are willing to pay the premium, then maybe Files would be a better choice.
Structured Data Scenario: Azure Tables is one mechanism for storing structured and semi-structured data, but it requires new ways of thinking about how to optimize for reads and writes, concurrency, transactions, etc. Azure SQL is a much more familiar to developers used to working with various flavors of SQL Server. The trade off is that SQL is much more expensive than tables, and is less scalable. Julie Lerman's article examining Azure Tables is a good introduction to how they can be adapted to structured data storage scenarios, while the lengthy Azure Storage Tables Design Guide does into great depth on patterns and practices to utilize tables in applications.
Message Queue Scenario: Storage Queues and Service Bus Queues are two messaging services offered by Azure. The MSDN article comparing them notes some of the key features of each that may make one or the other a better choice for your application. Need more than 80GB of messages? Storage Queues are the answer. Need messages for longer than 7 days, guaranteed ordering, or advanced integration patterns? You'll have to go with Service Bus Queue.
File Backup Scenario: Say we want to cheaply back up a bunch of files. The two mechanisms we might look at are Blobs and Files, each with their own strengths (StackOverflow's take). Blobs are roughly 30% or less the cost of Files per GB, and can store much greater total data per container. However, if SMB access is important, or maybe you have files that are bigger than 200GB (limit on a block blob), and you are willing to pay the premium, then maybe Files would be a better choice.
Structured Data Scenario: Azure Tables is one mechanism for storing structured and semi-structured data, but it requires new ways of thinking about how to optimize for reads and writes, concurrency, transactions, etc. Azure SQL is a much more familiar to developers used to working with various flavors of SQL Server. The trade off is that SQL is much more expensive than tables, and is less scalable. Julie Lerman's article examining Azure Tables is a good introduction to how they can be adapted to structured data storage scenarios, while the lengthy Azure Storage Tables Design Guide does into great depth on patterns and practices to utilize tables in applications.
Message Queue Scenario: Storage Queues and Service Bus Queues are two messaging services offered by Azure. The MSDN article comparing them notes some of the key features of each that may make one or the other a better choice for your application. Need more than 80GB of messages? Storage Queues are the answer. Need messages for longer than 7 days, guaranteed ordering, or advanced integration patterns? You'll have to go with Service Bus Queue.
Accessing Azure Data with PowerShell
With Azure PowerShell it is possible to manage storage accounts, create authentication tokens, and query and manipulate Azure Storage Blobs, Queues, Tables, and Files. The MSDN article on managing Azure storage with PowerShell dives pretty deep on the topic. The Blob, Table, and Queue commands are shown below, for a complete list of all storage related cmdlets you would change the "Noun" argument to "*Storage*":


Before running most of the commands, it is necessary to authenticate with Azure through the PowerShell interface. Running Add-AzureAccount in PowerShell will bring up the federated login screen. Simply enter the Microsoft account or Active Directory credentials associated with the Azure subscription. Once you've logged in, if you have multiple Azure accounts, you can select which one you want to be the default with Select-AzureSubscription:

You can create a new storage account with New-AzureStorageAccount, and set this as the default storage account for your subscription with Set-AzureSubscription. You can list all of the storage accounts in a subscription with Get-AzureStorageAccount. Finally, the article covers creating a storage context, which is an object that stores storage credentials. There are several ways to do it covered in the article, the first using Get-AzureStorageKey to get a key, and then passing that key to New-AzureStorageContext to create the context. Easy.
Managing Blobs with PowerShell
In articles explaining Azure Storage Blobs, it's not uncommon to see a hierarchy, starting with the Azure storage account, which has one or more "containers", each of which has one or more blobs, which may consist of one or more pages or blocks (depending on the type of blob). So before we can create Blobs, we much first create a container, which is accomplished with New-AzureStorageContainer. We provide the cmdlet the container name and permission level for anonymous reads, which can be set to off, blob, or container. "Off" is no read permission, "Blob" allows access to individual blobs, and "Container" allows blobs to be listed (as well as read individually), creating a neat spectrum from least to most permissive.
Writing to a blob is done with Set-AzureStorageBlobContent. Get-AzureStorageBlob returns a reference to a blob, while Get-AzureStorageBlobContent retrieves the actual blob content. There are also cmdlets to copy blobs between containers asynchronously. Finally, deleting a blob is done with Remove-AzureStorageBlob.
Blobs also support the notion of snapshots, which capture the state of a blob at a given moment in time and allow you to revert to this state (much like VM snapshots). Creating a snapshot is actually accomplished by calling an instance method on the blob reference returned by Get‑AzureStorageBlob. This same cmdlet can be used to list all the snapshots on a blob (with some fancy PowerShelling). Once a snapshot exists, Start-AzureStorageBlobCopy can be used to copy the snapshot content to a new blob.
Managing Tables with PowerShell
Azure tables are NoSql data stores that can be used to store massive amounts of structured data. Each "row" in a Table is called an entity (or table entity if you will). Many of the semantics around managing tables are the same as with blobs (although you don't need a container). Creating, retrieving, and deleting a table use the New‑AzureStorageTable, Get‑AzureStorageTable, and Remove‑AzureStorageTable, respectively.
Managing table entities is complicated by the fact that PowerShell does not directly support manipulating them. Instead, the documentation presents an example of using PowerShell to wrap functionality from the client library for .NET. The important thing to remember with table entities is that they must be uniquely identified by their partition key and row key. The Storage Table Design Guide includes extensive guidance on designating partition and row keys in such a way to support read and/or write operations on a table. I'll get into the gritty details when I look at using the client library in C# code below.
Managing Queues with PowerShell
Storage Queues are very similar to tables with respect to their PowerShell friendliness. Creating, retrieving, and deleting queues is very easy with New-, Get-, Remove-AzureStorageQueue cmdlets, while inserting and deleting message from a queue is a little less straight forward. Not quite as awkward as trying to manipulate table entities, it just requires creating a CLR object for the message and calling an instance method on the retrieved queue. I created a queue and a couple messages in just a few lines in the example below:
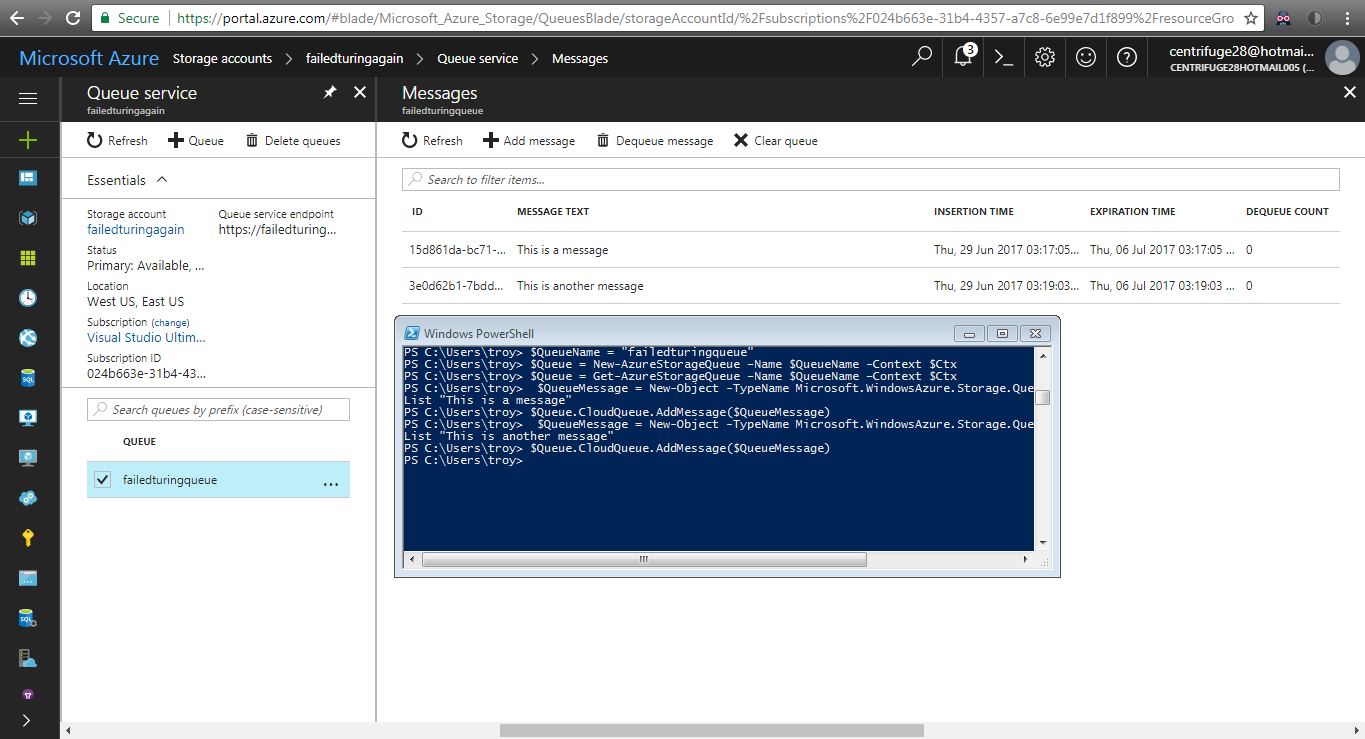
Calling the GetMessage method on the queue will de-queue the next message. This doesn't permanently remove the message from the queue, but instead make the message invisible for the timeout period (which is a value passed into GetMessage). When the timeout expires, the message reappears on the queue with an incremented DequeueCount property. The DequeueCount property is useful for detecting poison messages that cannot be correctly processed (I'll elaborate on that in the error handling section).
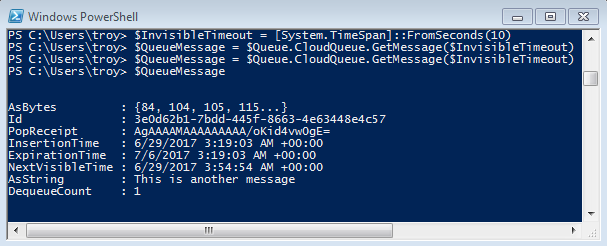
In the above example, I'm popping off two messages. Since the variable is reassigned, I lose the reference to the first message (making deletion impossible), and it will reappear on the queue in 10 seconds. If I call DeleteMessage before the timeout (passing the queue message reference as an argument), then the message will be permanently removed from the queue.
Accessing Azure Data with C#
The documentation for each of the major storage entities contains a "Get started with X using .NET" page:
There is also the Code Samples page, as well as the Azure Storage samples using .NET article. Finally, the storage emulator is invaluable for development and testing. Just make sure you have the latest version... I had 4.2 installed and the demo code through an HTTP 400 error... luckily StackOvervlow pointed out where in the exception I could dig down to get the the root of the problem. Upgrading to 5.1 solved my problem.
Before getting started with the demo code, there are two nuget packages that need to be installed: WindowsAzure.Storage, and Microsoft.WindowsAzure.ConfigurationManager:

My super simple demo app is basically just a little-changed adaptation of the "getting started" code. Really all I did is tie it together into a single console app. Since the code is pretty much lifted right off the MSDN site, I'm not going to insert it here (it is available in the GitHub repo). The console app isn't terribly interesting since all it does is create a blob (using a trollface image), add some metadata to a table entity, and then add a message to a queue:

- Get started with Azure Blob storage using .NET
- Get started with Azure Queue storage using .NET
- Get started with Azure Table storage using .NET
- Get started with Azure File storage on Windows
There is also the Code Samples page, as well as the Azure Storage samples using .NET article. Finally, the storage emulator is invaluable for development and testing. Just make sure you have the latest version... I had 4.2 installed and the demo code through an HTTP 400 error... luckily StackOvervlow pointed out where in the exception I could dig down to get the the root of the problem. Upgrading to 5.1 solved my problem.
Before getting started with the demo code, there are two nuget packages that need to be installed: WindowsAzure.Storage, and Microsoft.WindowsAzure.ConfigurationManager:

My super simple demo app is basically just a little-changed adaptation of the "getting started" code. Really all I did is tie it together into a single console app. Since the code is pretty much lifted right off the MSDN site, I'm not going to insert it here (it is available in the GitHub repo). The console app isn't terribly interesting since all it does is create a blob (using a trollface image), add some metadata to a table entity, and then add a message to a queue:
Using Azure CDN
In my post for 70-486 on reducing network bandwidth I walk through an example of using the Azure CDN to host a file from blob storage, so I won't do another detailed walk through. I think a high level overview, though, would still be helpful.
A CDN, or Content Distribution Network, is a service provider that has a widely distributed network of server that serve cached content to users. Often, this content is static files, and can be CSS files, multimedia files, anything that doesn't need to change frequently. By serving these files from the CDN provider instead of from your own servers, it not only reduces the traffic on your network, but also provides a snappier user experience for end users.
For a long time, CDNs were only available from the classic portal, however it seems this is beginning to change. In a May 2016 episode of Azure Friday, Scott Hanselman talks with one of the Microsoft program managers about the (then) new features of CDN being made available in the portal. In another episode, Seth Juarez discusses adding Akamai as a CDN provider. Based on the detailed pricing features, it seems that Akamai has some tradeoffs compared to the Verizon Standard CDN (adds Media optimization, but no Custom domain HTTPS).

A CDN, or Content Distribution Network, is a service provider that has a widely distributed network of server that serve cached content to users. Often, this content is static files, and can be CSS files, multimedia files, anything that doesn't need to change frequently. By serving these files from the CDN provider instead of from your own servers, it not only reduces the traffic on your network, but also provides a snappier user experience for end users.
For a long time, CDNs were only available from the classic portal, however it seems this is beginning to change. In a May 2016 episode of Azure Friday, Scott Hanselman talks with one of the Microsoft program managers about the (then) new features of CDN being made available in the portal. In another episode, Seth Juarez discusses adding Akamai as a CDN provider. Based on the detailed pricing features, it seems that Akamai has some tradeoffs compared to the Verizon Standard CDN (adds Media optimization, but no Custom domain HTTPS).
A year ago, the pricing tiers were a bit different, as there was no notion of which provider could be used (it was all Verizon under the hood), and the highlighted features were different. Contrast the pricing above with that included on my "Reduce Network Bandwidth" post.
Handling Transient Failures with Retries
The three MSDN articles cover transient fault tolerance in varying levels of detail. The article on Azure Storage retry recommendation is very targeted, and is also brief, being maybe a five minute read. The Transient fault handling article is a more general guide to why transient failures happen and offers some general approaches to dealing with them. The article on service specific retry guidance is the most granular. It is a much longer read at 40 minutes, but it also includes code samples. The last module in the PluralSight Azure Storage In Depth course is also dedicated to transient fault handling.
Cloud based services are prone to transient failures for a number of reasons. Services in shared environments may be subject to throttling, individual servers may run out of available connections, hardware can fail, and layers of routers and load balancers adding latency and additional points of failure. One of the challenges of dealing with these temporary faults is distinguishing them from longer lasting or even fatal errors. Handling these failures can involve retrying a request if it is likely that a subsequent attempt will succeed. The nature of the failure will determine what kind of retry strategy is appropriate. The Transient fault handling MSDN article lists a few of these strategies:
Cloud based services are prone to transient failures for a number of reasons. Services in shared environments may be subject to throttling, individual servers may run out of available connections, hardware can fail, and layers of routers and load balancers adding latency and additional points of failure. One of the challenges of dealing with these temporary faults is distinguishing them from longer lasting or even fatal errors. Handling these failures can involve retrying a request if it is likely that a subsequent attempt will succeed. The nature of the failure will determine what kind of retry strategy is appropriate. The Transient fault handling MSDN article lists a few of these strategies:
- Immediate Retry: some faults may be caused by a rare one-off event, and retrying immediately, without any delay, will succeed. The guidance is adamant that this should only every be done once, that is, don't immediately retry multiple times in quick succession; if one immediate retry doesn't work, either fall back to some retry delay strategy, or fail.
- Fixed Interval Retry: each retry waits the same amount of time.
- Increasing Interval Retry: with each retry, the interval until the next retry becomes longer. This can be an incremental increase (say, the interval increases by 4 seconds each time, so 3, 7, 11, 15, etc) or this can be a multiplicative increase (commonly called "exponential" retry, so maybe 2, 4, 8, 16, 30, 60 seconds).
- Randomization: to avoid multiple processes retrying requests on the same intervals (possibly as the result of the same underlying failure), it can be helpful to include an element of randomization to offset retry request.
The MSDN guidance suggests using exponential backoff for services such as web service calls and database, and immediate and/or fixed interval retry strategies for "interactive" operations. It also takes pains to emphasize that the total request time should also be taken into consideration when designing a retry strategy. Furthermore, transactional requests that rely on more than one resource or service may present additional challenges (depending on whether individual requests are idempotent).
Two articles on patterns, Circuit Breaker and Retry, also address strategies for dealing with faults from remote services and resources. The Retry article mostly restates many of the same concepts around transient error handling. The Circuit Breaker pattern, on the other hand, is a pattern primarily intended to detect non-transient faults. The circuit breaker is implemented as a service proxy, and when services are expected to be unavailable (based on criteria such as the number and type of recent failures to that service) the circuit breaker code will "open" and return an exception to calling code. By failing at the circuit breaker, fewer requests to the remote resource are made (important if the failure is related to constrained network or database connections, for example). The circuit breaker can then implement it's own retry policy.
From a practical standpoint, certain client libraries include their own retry policy implementations. Those for Entity Framework 6+, the Azure Storage client, and the Azure Redis StackExchange client are touched on in the service specific retry guidance article.
In the Azure Storage namespace, there are two interfaces, IRetryPolicy and IExtendedRetryPolicy, which are used to define retry policies for Azure Storage operations. The built in LinearRetry and ExponentialRetry classes implement the IExtendedRetryPolicy (which itself extends IRetryPolicy). Both the LinearRetry policy and ExponentialRetry policy can be constructed with a specific time interval and retry count, though the meaning is different. In the linear retry policy, the time interval is fixed between retries, whereas in the exponential retry policy, the interval is multiplied by 2 raised to the current retry count (based on the source code). Both built in policies also take into account the time spent on requests (so if the retry interval is 5 seconds and the requests takes 3, it will only wait another 2 seconds). Naturally, implementing the IExtendedRetryPolicy interface would allow you to define a custom policy. The policy (whether built-in or custom) is configured as part of building up an "Options" object, a flavor of which exists for each of the Azure Storage types (Table, Queue, Blob, or File).
Transient failures to Azure SQL can be handled differently, depending on which data access technology is making the request. Entity Framework 6+ includes a collection of APIs called Connection Resiliency and Retry Logic, which includes several "Execution Strategies", one of which is tailored for Azure SQL and will retry automatically when transient failures are encountered (just be mindful of some of the limitations imposed by using a retrying strategy, such as no streaming queries or user transactions). For older versions of Entity Framework, the Transient Fault Handling Application Block (Part of Enterprise Library) is one alternative. This library includes strategies not only for SQL, but for Azure Service Bus and Azure Storage as well (though for Storage, the recommendation is to use the storage client built in retry strategies).
The Azure Service Bus namespace includes two retry policy classes: NoRetry and RetryExponential. What NoRetry does seems pretty obvious. RetryExponential, as with the storage client version, defines an increasing backoff strategy. The constructor takes a min and max backoff and a retry count. Code that appears to be for the next version is available from GitHub, with a different namespace (Microsoft.Azure.ServiceBus), and a constructor that additionally takes a deltaBackoff parameter.
Finally, the service specific guidance also offers insight on using the StackExchange client for Redis with Azure Redis (since Azure Managed Cache is basically dead). Apparently most of this is handled directly by the client, though the timeout, retry count, and policy (linear or exponential) are all configurable.
From a practical standpoint, certain client libraries include their own retry policy implementations. Those for Entity Framework 6+, the Azure Storage client, and the Azure Redis StackExchange client are touched on in the service specific retry guidance article.
In the Azure Storage namespace, there are two interfaces, IRetryPolicy and IExtendedRetryPolicy, which are used to define retry policies for Azure Storage operations. The built in LinearRetry and ExponentialRetry classes implement the IExtendedRetryPolicy (which itself extends IRetryPolicy). Both the LinearRetry policy and ExponentialRetry policy can be constructed with a specific time interval and retry count, though the meaning is different. In the linear retry policy, the time interval is fixed between retries, whereas in the exponential retry policy, the interval is multiplied by 2 raised to the current retry count (based on the source code). Both built in policies also take into account the time spent on requests (so if the retry interval is 5 seconds and the requests takes 3, it will only wait another 2 seconds). Naturally, implementing the IExtendedRetryPolicy interface would allow you to define a custom policy. The policy (whether built-in or custom) is configured as part of building up an "Options" object, a flavor of which exists for each of the Azure Storage types (Table, Queue, Blob, or File).
Transient failures to Azure SQL can be handled differently, depending on which data access technology is making the request. Entity Framework 6+ includes a collection of APIs called Connection Resiliency and Retry Logic, which includes several "Execution Strategies", one of which is tailored for Azure SQL and will retry automatically when transient failures are encountered (just be mindful of some of the limitations imposed by using a retrying strategy, such as no streaming queries or user transactions). For older versions of Entity Framework, the Transient Fault Handling Application Block (Part of Enterprise Library) is one alternative. This library includes strategies not only for SQL, but for Azure Service Bus and Azure Storage as well (though for Storage, the recommendation is to use the storage client built in retry strategies).
The Azure Service Bus namespace includes two retry policy classes: NoRetry and RetryExponential. What NoRetry does seems pretty obvious. RetryExponential, as with the storage client version, defines an increasing backoff strategy. The constructor takes a min and max backoff and a retry count. Code that appears to be for the next version is available from GitHub, with a different namespace (Microsoft.Azure.ServiceBus), and a constructor that additionally takes a deltaBackoff parameter.
Finally, the service specific guidance also offers insight on using the StackExchange client for Redis with Azure Redis (since Azure Managed Cache is basically dead). Apparently most of this is handled directly by the client, though the timeout, retry count, and policy (linear or exponential) are all configurable.
Azure Redis Caching
The Exam Ref only looks at Azure Managed Cache, which has since been retired. I look at both in my previous post on Designing a Caching Strategy for 70-486, so I don't think beating it to death here is necessary.
Depending on the service tier, Redis Cache is available with limits from 53GB to 530GB, and 99.9% availability. Redis is more than just a key/value store, as it also has support for a number of atomic operations such as appending to a string, incrementing a hash value, etc. It also supports transactions, pub/sub, and other features.
Depending on the service tier, Redis Cache is available with limits from 53GB to 530GB, and 99.9% availability. Redis is more than just a key/value store, as it also has support for a number of atomic operations such as appending to a string, incrementing a hash value, etc. It also supports transactions, pub/sub, and other features.
The Microsoft documentation I've seen dealing with Redis cache has always used the StackOverflow client for Redis. The How-To article demonstrates creating, managing, and using a Redis cache, with examples in C# using the StackOverflow client. Most of the creation and configuration examples in the article use the Azure Portal or PowerShell, while setting and getting values to and from the cache are demonstrated using C# code.
I wrote up a quickie demonstration in less than an hour (it's reading and writing cache, not exactly rocket science lol):
static void Main(string[] args) { var connectionString = @"***.redis.cache.windows.net:6380,password=***,ssl=True,abortConnect=False"; ConnectionMultiplexer connection = ConnectionMultiplexer.Connect(connectionString); IDatabase cache = connection.GetDatabase(); ISet<string> keys = new HashSet<string>(); for(string key = " "; key != ""; ) { Console.Write("\n\nEnter a key (empty to quit): "); key = Console.ReadLine(); if(key != "") { Console.Write("\nEnter a value: "); string value = Console.ReadLine(); cache.StringSet(key, value); keys.Add(key); } Console.WriteLine("\nCurrent Values in the cache: "); foreach(string k in keys) { if (cache.KeyExists(k)) { Console.WriteLine(" " + k + ": " + cache.StringGet(k)); } } } }

While it wasn't terribly difficult, there were a couple of things that (briefly) tripped me up. The first was that the connection string is sensitive to extra white space. The first time I pasted it in, it was not enclosed in quotes, and Visual Studio tried to get cute. This resulted in the client throwing a weird error related to authentication. When I recopied the connection string, it worked. The second small stumble was that SetAdd doesn't mean "Set" in the sense of "set a value"... it means "Set" as in the data collection. When I went to call "StringGet", the client threw an exception complaining about the datatype mismatch. So make sure your datatypes are matching up. Code available on GitHub.
No comments:
Post a Comment