I'm hoping that working through this class will sharpen my understanding of general software engineering concepts. The emphasis of the class is writing bug free code that is easy to understand and easy to change, which is certainly something you can never be too good at, am I right?
For organizational purposes, I'm going to divide the readings from the edX class into arbitrary "weeks" of two readings each, plus whatever corresponding p-sets or tutorials go along with them.
Part 1 (6.005.1x)
Week 1
The first week was pretty basic. Reading 1 covers static checking, primarily by comparing static typing (as in Java) with dynamic typing (as in Python). Type information and the final keyword can make the intent of the code more clear and eliminate certain buggy behavior. The Big Idea for this reading is that our code should meet three criteria:
- Safe from bugs
- Easy to Understand
- Ready for change
These three goals serve as a common theme throughout the first two readings, and I suspect this will continue throughout the course. The second reading is "Code review" and basically is a quick overview of several best practices, like fail fast, don't repeat yourself (DRY), avoid magic values, use good variable names, and use consistent white space. If one has read The Pragmatic Programmer, then much of this section will ring very familiar.
The homework for this week is the first part of the "Java Tutor". They didn't have a direct link in the edX course that I could find, but I did find it on the MIT site: Java Tutor. I tried installing the software in Eclipse Luna and it didn't work, so I updated to Neon and it installed fine. Unfortunately, it seems the it is no longer possible to get a "personal start url", through edX or MIT's course page. I'm not sure I need a basic Java tutorial personally, but in the spirit of "doing all the work" I can go over to HackerRank and bang out their Java Domain challenges. (If I'd read the announcements carefully, I'd have noticed that they specifically mention that the Java Tutor is no longer available)

While plenty of the challenges were trivial, there were a few good ones in there (and a few ridiculous ones as well). Overall a worthwhile exercise, and now I'm tied with about 1000 other people for rank 1 whoohoo! </sarcasm>
Reading for this week cover testing and specifications. Reading 3 focuses on testing, touching on blackbox vs whitebox testing, unit vs integration testing, regression testing, and code coverage. Most of the material was review, but I did find the discussion about systematically partitioning input in order to design the test suite informative. While I've generally tried to think about edge and corner cases, I think I've still been largely guilty of "haphazard" testing. The partitioning approach puts some structure and logic around designing test inputs.
Reading 4 is a primer on specifications. A specification defines the "contract" a given piece of code needs to adhere to, including what inputs are acceptable and what outputs can be expected. Spent some time on preconditions and postconditions, and the difference between checked and unchecked exceptions.
The first p-set is a "warm up". It basically involves implementing the quadratic equation to find the integer roots of an equation in the form of ax² + bx + c, where the coefficients are passed in as integers. While trivially simple at first glance, there are a number of corner cases that can trip you up. What happens if 4ac > b²? What if any of the coefficients are zero? What if the roots are not integers? There is a decent test suite for the "beta" p-set, and several tests in the "final" suite catch some of the less obvious edge cases.
It was a bit of a headache getting the autograder script to run right at first (issue with the build path in Eclipse and ant I think). The trick was to import each p-set as it's own project in Eclipse. They still live in the same folder hierarchy (and thus git repo), but Eclipse doesn't get confused that way, and ant runs the autograder without issue.
The next two readings cover designing specifications and "avoiding debugging".
Good specifications exhibit a number of important properties:
P-set 2 is substantially more involved that the first was. The premise was that we were given specifications, and we had to implement those specifications and a test suite. Our implementation is run through a battery of tests, but what I thought was really thought provoking was that the autograder ran a good and bad implementation of the spec against our test suite. So to pass, you needed not only a good implementation, but tests that correctly exercise the spec. Here are my results (which I finally achieved at midnight... yaaawn...)

While plenty of the challenges were trivial, there were a few good ones in there (and a few ridiculous ones as well). Overall a worthwhile exercise, and now I'm tied with about 1000 other people for rank 1 whoohoo! </sarcasm>
Week 2
Reading for this week cover testing and specifications. Reading 3 focuses on testing, touching on blackbox vs whitebox testing, unit vs integration testing, regression testing, and code coverage. Most of the material was review, but I did find the discussion about systematically partitioning input in order to design the test suite informative. While I've generally tried to think about edge and corner cases, I think I've still been largely guilty of "haphazard" testing. The partitioning approach puts some structure and logic around designing test inputs.
Reading 4 is a primer on specifications. A specification defines the "contract" a given piece of code needs to adhere to, including what inputs are acceptable and what outputs can be expected. Spent some time on preconditions and postconditions, and the difference between checked and unchecked exceptions.
The first p-set is a "warm up". It basically involves implementing the quadratic equation to find the integer roots of an equation in the form of ax² + bx + c, where the coefficients are passed in as integers. While trivially simple at first glance, there are a number of corner cases that can trip you up. What happens if 4ac > b²? What if any of the coefficients are zero? What if the roots are not integers? There is a decent test suite for the "beta" p-set, and several tests in the "final" suite catch some of the less obvious edge cases.
It was a bit of a headache getting the autograder script to run right at first (issue with the build path in Eclipse and ant I think). The trick was to import each p-set as it's own project in Eclipse. They still live in the same folder hierarchy (and thus git repo), but Eclipse doesn't get confused that way, and ant runs the autograder without issue.
 |
| Autograder with failing tests |
 |
| Autograder with all passing tests |
 |
| Double clicking the grading report brings up the Junit results |
Week 3
The next two readings cover designing specifications and "avoiding debugging".
Good specifications exhibit a number of important properties:
- Declarative (vs Operational): declarative specifications don't dictate the internal implementation details of the method or class being specified.
- Balanced Spec Strength: Specs that are too strong (weak preconditions and/or strong postconditions) limit the flexibility of the implementation, while specs that are too weak may not give clients enough information.
- Determinism: A spec is deterministic if a valid set of inputs can product one output. "Underdetermined" specs may product different "right" outputs with different implementations. This differs from "non deterministic" output, which has an element of randomness.
- Coherence: The spec should be doing one thing, and pre and post conditions should be logically consistent (i.e. avoid situation like "you can have any color you like, as long as it's black").
I found the discussion of spec strength particularly interesting. When comparing two specs, it is useful to be able to determine if one spec could be substituted for another without breaking existing clients. If Spec2 is stronger than Spec1, then it can be substituted. The pre and post conditions of the spec determine it's strength. A spec with weaker preconditions or stronger postconditions (that is, less restrictive or more restrictive, respectively) is a stronger specification.
One thing that tripped me up on the exercises: when comparing pre/post conditions, it is possible that they are incomparable. This can be subtle. Look at this example from the exercises:
- returns lowest index i such that a[i] = val
- returns index i such that a[i] = val, or -1 if not such i
Condition 1 is more restrictive with respect to the acceptable value of i (in two, i can be any i such that a[i] = val), however condition 2 is more restrictive with respect to how to behave if val is not in the array. So these two are not comparable.
The second reading covers avoiding bugs. One way this can be accomplished is through static checking (the compiler won't let you assign an int to a String) and immutability (you can't reassign a variable marked as final). An important pitfall with final is that only object references are immutable when final is applied to an object. So a final List<> can still have items added and removed.
Localizing bugs and writing modular code also serve to minimize debugging. Minimizing variable scope and using assertions to check pre and post conditions (when it makes sense to do so) are two techniques to this end. Variable scope can be minimized by declaring variables only at the point they are needed (and of course, avoid global variables like the plague). Assertions on preconditions allow methods to fail fast rather than letting invalid values propagate through the system. Asserting on postconditions (also called a "self check") can verify that the code is returning valid outputs to the client.
P-set 2 is substantially more involved that the first was. The premise was that we were given specifications, and we had to implement those specifications and a test suite. Our implementation is run through a battery of tests, but what I thought was really thought provoking was that the autograder ran a good and bad implementation of the spec against our test suite. So to pass, you needed not only a good implementation, but tests that correctly exercise the spec. Here are my results (which I finally achieved at midnight... yaaawn...)
 |
| Most of those 141 test cases are just in the autograder... |
Week 4
Reading 7 covers mutability and immutability. Immutable type cannot be changed once they have been assigned a value. String is an example of an immutable type. When a string is “changed”, what actually happens is that a new string is created and the reference to the old string is pointed at the new string. Mutable types can be changed without affecting their references. Lists and StringBuilder are mutable types, that is to say, the data they hold can be changed without changing their object references. This can potentially lead to unintended side effects and bugs.
One consequence of mutability is that contracts become less localized. The state of an object is no longer a function of the method or class being specified, but also depends on the good behavior of any other code that holds an alias. Caching and returning object references is one way that shared references can sneak into an implementation and wreck havoc.
Reading 8 covers debugging. The first step to systematic debugging is to reproduce the buggy behavior. One approach to making bugs easier to identify and reason about is to use as small a test case as possible (that still exhibits incorrect behavior).
To localize and understand the bug, use the scientific method:
- Study the data - test input, incorrect results, failed assertions, stack traces.
- Hypothesize - general hypothesis about where bug is and isn’t in the code.
- Experiment - test hypothesis as unobtrusively as possible - break points, print statements, unit tests, etc.
- Repeat - add collected data to previous data, make fresh hypothesis
Other tips include:
- Localize bugs with binary search - repeatedly divide search space in half using various probes to determine at what point results are turning incorrect.
- Prioritize hypotheses - Older, well tested code is less likely to have a bug than new code, and Java Library code is even more trustworthy.
- Swap components - if you have another module that fulfills the same contract, try that instead (e.g. if you are debugging binarySearch(...), try linearSearch(...)).
- Make sure source and object code are up to date - try cleaning out project binaries and rebuilding.
- Get help - talk to a rubber duck if you have to.
Finally, when it comes time to fix the bug, don’t just slap on a patch and move on. Think about what caused the bug, what other clients may be affected by the bug, other places the same bug might appear. When the bug is fixed, add the test cases to the test suite and run the full suite to ensure you didn’t introduce new bugs.
Week 5
Reading 9 covers Abstract data-types (ADTs). These datatypes are characterized by their operations rather than their underlying representation. The idea of concealing the internal implementation of a type is sometimes called abstraction, encapsulation, or information hiding (among other names).
Operations in ADTs can be classified in several ways:
Several guidelines can improve the design of an ADT:
If an ADT is well specified, then the implementation of the ADT can be freely changed without breaking clients of the ADT.
One of the review questions has us look at the ideas of specification, representation, and implementation of an ADT. The specification is the external api of the ADT, and includes JavaDocs, class name, and method signatures. The representation is the internal data representation, so the internal, private fields. The implementation is the body of the operations, i.e. the methods implementing the ADT’s interface.
Reading 10 covers “abstraction functions” and representation invariants. Invariants are a concept I’ve seen before (probably in 6.006, but maybe 61B), which basically is a property of an ADT that is always true. Immutability is an example of an invariant. If the value of an object can never be changed, it makes reasoning about that object simpler, because we never have to wonder if another part of our code has changed the object.
The abstraction function maps a representation to an abstraction. The example used in the course is an ADT called “CharSet”, which has as it’s underlying representation a String. “abc” and “cab” would be representations that would both map to {a, b, c}. “abbc” would not map to anything since the abstraction doesn’t allow for duplicates. A representation that maps to an abstract value is said to satisfy the representation invariant.
It’s good to document the rep invariants, abstraction function, and safety from rep exposure in the class. Rep exposure is a particularly insidious problem, as it prevents the ADT from ensuring its invariant hold true for the life of the object (and class with a reference to the exposed mutable object can change it in ways that violate the ADT’s invariants). The “Safety from rep exposure” comment in an ADT forces you to reason about and justify why rep exposure is not a danger in this particular ADT.
Operations in ADTs can be classified in several ways:
- Creator - creates new object of type. Literals (“string”, 1, true) are creators, as are constructors and static factory methods.
- Producer - creates a new object from old object of that type. Arithmetic operations and string instance methods (concat, replace, etc.) are examples.
- Observers - take object of ADT and return objects of different type. .size() and .get() methods on lists, for example.
- Mutators - change (mutable) objects. May return void or some other value or object.
Several guidelines can improve the design of an ADT:
- a few, simple operations that can be composed
- coherent behavior (instead of a combination of many special cases)
- adequate - must do what clients will want it to do
- single level of abstraction - cannot be both generic and domain specific
If an ADT is well specified, then the implementation of the ADT can be freely changed without breaking clients of the ADT.
One of the review questions has us look at the ideas of specification, representation, and implementation of an ADT. The specification is the external api of the ADT, and includes JavaDocs, class name, and method signatures. The representation is the internal data representation, so the internal, private fields. The implementation is the body of the operations, i.e. the methods implementing the ADT’s interface.
Reading 10 covers “abstraction functions” and representation invariants. Invariants are a concept I’ve seen before (probably in 6.006, but maybe 61B), which basically is a property of an ADT that is always true. Immutability is an example of an invariant. If the value of an object can never be changed, it makes reasoning about that object simpler, because we never have to wonder if another part of our code has changed the object.
The abstraction function maps a representation to an abstraction. The example used in the course is an ADT called “CharSet”, which has as it’s underlying representation a String. “abc” and “cab” would be representations that would both map to {a, b, c}. “abbc” would not map to anything since the abstraction doesn’t allow for duplicates. A representation that maps to an abstract value is said to satisfy the representation invariant.
It’s good to document the rep invariants, abstraction function, and safety from rep exposure in the class. Rep exposure is a particularly insidious problem, as it prevents the ADT from ensuring its invariant hold true for the life of the object (and class with a reference to the exposed mutable object can change it in ways that violate the ADT’s invariants). The “Safety from rep exposure” comment in an ADT forces you to reason about and justify why rep exposure is not a danger in this particular ADT.
Week 6
Interfaces is the topic of Reading 11. Interfaces separate the abstraction from the implementation for an ADT. An interface in Java is just a list of method signatures, with no concrete implementation. The interface specifies the contract with the client. By specifying this contract in an interface, the client can’t become dependent on the ADT’s representation.
It is important to keep in mind that just because a class correctly implements an interface, this does not automatically mean that it correctly implements the ADT’s spec. If a spec requires an ADT to be immutable and an implementing class adds a mutator method, this is a violation of the specification (even if it doesn’t result in compile or runtime errors).
Finally, Reading 12 covers equality. There are several ways to think about equality from a conceptual standpoint. One is based on the abstraction function. If two ADTs map there representation to the same abstract value, they are equal. Another way to think about equality is using equivalence relations, which are basically like thinking of them in terms of mathematical concepts such as reflexivity (object equals itself), symmetry (a == b ⇒ b == a) and transitivity (a == b, b == c ⇒ a == c). The last way to think of equality is by observation. If two objects are indistinguishable (observer operations all return same results), then it can be said they are “equal”.
Java has two ways of testing for equality. The == operator tests for referential equality. For Object types, this means that two object references are pointing to the same address in memory (that is, the same object instance). Object, or content, equality is tested using the equals() method, which must be implemented by each ADT. One pitfall with overriding the equals() method of the base Object class is that the method signature for object.equals() takes an Object as an argument. If we take an instance of our ADT as an argument, we will overload, rather than override, the equals() method.
While instanceof is necessary when implementing the equals() operator, 6.005 strongly discourages its use elsewhere in our code, as well as other runtime type checking operations like getClass().
When we override equals, we generally must also override hashCode in order to ensure that we are still abiding by the Object contract. Because the base Object class uses referential equality for equals and hashCode, an ADT that implements object equality but inherits the default reference based hashCode will produce inconsistent results (i.e. to “equal” objects will hash to different values). This can wreck havoc on hash based data types (HashSet, HashMap).
The second to last reading video points out a trap you can fall into with mutable data types. If the hash is calculated based on the current state, it’s possible that a mutable object can be placed in a hash bucket, subsequently mutated (changing the hash value) without updating which bucket it is placed in, and as a result it can no longer be found by the ADT. The conclusion the course reaches is that mutable types should just inherit equals and hashCode from Object.
One final pitfall of equality relates to autoboxing with primitive types and the == operator. Where == mean referential equality with the object types (Boolean, Integer), it implements behavior equality with primitive types (boolean, int). Boxing and unboxing operations may obscure which type the operator is actually working with, creating subtle bugs.
P-set 3 focuses on implementing several ADTs (books, copies of books, and libraries of books). We're asked to really think about the representation, how to avoid exposing that representation, checking the rep invariant, and testing the interface. Not as heavy in the testing as pset 2 (though I did write a ton of tests for my Book ADT).

The final exam was pretty easy, most of the questions showed up in the reading exercises, and you got partial credit for imperfect answers. I got a 96% and I suspect one could get about 50% without trying. Here is my final progress report for "Software Construction In Java":

Part 2 (6.005.2x)
Week 7
This is the first module for the continuation on edX, Advanced Software Construction in Java. This weeks readings cover recursion and recursive data types. Sadly, they decided not to do video lectures for the second half of the course, so I hope to be able to find some relevant material to support the edX readings and assignments. The reading starts out with some basic review of recursion. I thought these videos from Computerphile (What on Earth is Recusion?) and Khan Academy (Comparing Iterative and Recursive Factorial Functions) support this introduction well. This is pretty basic yet so I won't belabor it.Part of creating a recursive solutions is breaking down the problem into recursive steps. This involves deciding on the base case and the recursive steps. They use the example of calculating all subsequences (which Tushar Roy walks through on YouTube). The base case is the point at which the problem can't be decomposed any further, such as the empty string in the subsequence problem, or fib(1) or fact(1), both of which equal 1.
The recursive step is sometimes easier to define in a private helper function that adheres to a different contract than the original method. The reading makes a point of emphasizing that this helper method should not be exposed to clients (it should be private). An even worse ideas is to use static global variables in lieu of recursion (bad, bad juju...).
In addition to recursive problems, like Fibonacci and factorial, there are also recursive data structures. The reading uses the example of a file system. Most tree implementations are another example. When you get the child of a node, that child is itself another "node", and could define a proper tree of its own right.
Reentrant code is code that is safe to leave and then restart. Recursive calls rely on this property to function properly. When we call fib(3), that execution is on hold while we calculate fib(2) and fib(1). For code to be reentrant, it can't rely on global variables or shared references to mutable objects (basically the environment can't change while the cpu is off executing something else). The wikipedia article points out that just because code is reentrant, this is not sufficient to guarantee that it is thread safe in concurrent code.
When combined with immutable variables and objects, recursive code leads to a style of programming called functional programming, where every method call is a pure function.
Reading 2 covers recursive data types in detail. We look at immutable lists and revisit some of the terminology from SICP. Our immutable list is represented by an interface, ImList, with two implementations, Empty and Cons, which represent empty and non-empty lists respectively.
This reading introduces a syntax for writing "data type definitions". These definitions consist of an abstract data type on the left hand side, and its representation on the right. A generic tree declaration would look like this:
Tree<E> = Empty + Node(e:E, left:Tree<E>, right:Tree<E>)
This basically says a tree can consist of empty nodes, or of nodes that contains a left and right child that are themselves Tree<E> (thus making this a recursive datatype).
Because an empty list is represented by an object, instead of null, we avoid much of the unpleasantness that comes with null checks everywhere. Empty and Cons are examples of polymorphism, since they both implement the same interface. At compile time, any objects declared as ImList have ImList as their declared type, while at runtime, their actual type is either Empty or Cons. ImList cannot be an actual type, because interfaces do not have constructors (i.e. they cannot be instantiated). The exercise for this nugget tripped me up: Variables have only a declared type, and objects have only an actual type:
variable, declared type => String foo = "bar" <= object, actual type
The one big idea that I thought was worth mentioning is this: recursive datatypes allow us to represent unbounded structures. No pset this week.
Week 8
Week 4 of the Introduction to Natural Language Processing also covers grammars (formal grammar), so at least I had an element of familiarity going into this week's material. I found a lecture from an NPTEL class on programming languages that covers grammars. It goes deeper into the theory around context-free and regular grammars than the reading does. The reading focuses more on concrete examples, which actually makes for a nice complement. I found a couple videos to "support" the regex part of the reading, but one of them devolved into overly mechanical examples, and the ones from Coding Rainbow were... just too over the top for my taste.
A grammar is really just a set of rules for generating parse trees for a string. A Context Free Grammar is usually specified in the for A ::= B C, where B and C can represent either terminal or non-terminal symbols. These expressions may include a number of operators, similar to what we've seen in regular expressions (*, +, ?, | for example). A regular expression is a parsing rule that can be fully specified in one line (that is, there is no recursion). The reading gives the counter example as a bit of HTML, where the definition of italics includes the definition of html, and thus can't be expressed as one since statement.
Reading 4 covers parser generators, mostly by providing a walkthrough of how to use the custom parser they developed for the course, ParserLib. ParserLib is (allegedly) a simpler, easier to use library compared to popular parsers like ANTLR (this lecture by Terence Parr, who created ANTLR, is worth watching). Another good video, suggested in the discussion section, goes over converting a grammar to a parse tree. For additional reading, I would suggest the wikipedia articles on abstract syntax tree and recursive decent parser.
Getting the code samples to work required a bit of finagling and digging. I had to massage some of the code to cooperate with my particular environment (the path to the grammar file was giving me fits). Once that was running, the reading started going over some of the code for navigating the parse tree, which referenced classes and interfaces that weren't presented in the material. Fortunately the Fall 2016 page for the on campus class pointed to a GitHub repo with the missing bits, so I was able to get that running too.
Below is what my basic demo code looks like:
public static void main(String[] args) throws Exception{ Parser<IntegerGrammar> parser = GrammarCompiler.compile(new File(getPath(), "IntegerExpression.g"), IntegerGrammar.ROOT); ParseTree<IntegerGrammar> tree = parser.parse("5+2+3+21"); System.out.println(tree.toString()); //Display a graph of the tree in a web browser tree.display(); System.out.println("\n\nIndented representation of tree:"); visitAll(tree, " "); } private static String getPath(){ return "src/" + Main.class.getPackage().getName().replaceAll("\\.","/"); }
Output:

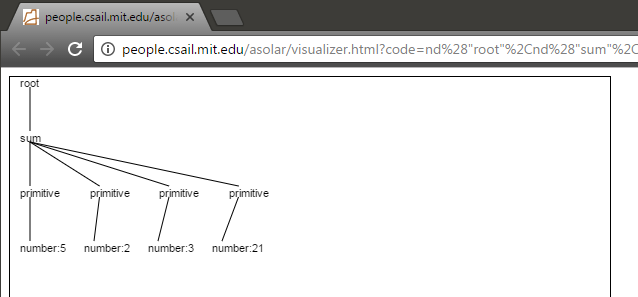
Problem Set 4 has us building a grammar for parsing polynomials. It's basically broken down into 4 parts: building the grammar, building the abstract representation, derivation, and simplification. The problem actually has us trying to come up with the abstract data type first, but I actually ended up making a lot of tweaks once I got the grammar figured out, so in my mind it makes sense to do the grammar first. Maybe if I was better at grammar I could have fit the grammar to my ADT...
¯\_(ツ)_/¯
One of the challenges was making sure the resultant expression tree honored PEMDAS operator precedence. My first thought was to try to implement this as part of the ADT (actually it's an abstract syntax tree, so I'll call it the AST instead). I quickly realized this was going to be a major pain, so I started looking into whether this could be handled in the grammar itself. I found a couple good references: scribe notes from a Harvard class, and the Wikipedia article for Operator Precedence Parser. The approach the Harvard notes takes actually proved unworkable, since the parser included with the project doesn't support left recursion. Then I stumbled on the operator precedence parser and that got me across the finish line, as far as parsing was concerned.
Once I had a grammar it became much more clear how I had to handle turning into an abstract syntax tree. One thing that tripped me up (and I wasn't the only one)... while the grammar can be specified to skip whitespace, the whitespace nodes still show up in the parse tree.

It's easy enough to work around, just have to be aware of it (I used a helper method to filter those nodes out). My AST consisted of 4 node types: Multiplication, Addition, Number, and Variable, all of which implemented the Expression interface. The question was asked "why bother with an AST when we already have a parse tree?", and for me the answer was very clear by the end of this pset. Your AST can simplify the tree (I didn't need nodes for ROOT, EXPRESSION, or PRIMITIVE), and Expressions can implement methods that make sense for that expression type. How a Number handles differentiation is very different compared to how Multiplication handles it. Same with simplification.
Speaking of simplification, that was a tough nut to crack. We are explicitly instructed not to use any kind of type introspection, but the problem is how to we perform mathematical operation when a child node can have a numerical or a symbolic representation? My solution was to have each Expression implementation return an class that included a symbolic string as well as maybe a numerical value (i.e. an option type). Now, I defined my own Maybe<T> class instead of using the built in Optional<T> java type (didn't realize it existed). So, given an environment, Multiplication and Addition will get evaluators for all their children, and collect any numerical values they can. Numeric values are aggregated using the appropriate operator, and then combined with any remaining purely symbolic values. If the value is strictly numeric, these operations will return that in a Maybe, otherwise only the symbolic string will be used. It is probably overly clunky, but it passed the grader so... good enough for me.
{After final grader comes out}
After timing out on a left nested expression, I had to tweak my grammar a bit. There were a couple other small bug fixes to pass the test suite (including fixing the grader itself, smh...). The edX grader is basically meaningless, since you only need to pass a handful of tests to get full credit. I'm beginning to get the sense that the staff didn't put a whole lot of energy into this offering... oh well.
Week 9
This week is pretty short and sweet as far as new material goes. Reading 5 is basically an introduction to concurrency, to which I thought this Google talk on the subject was an excellent complement. The reading seems to present a broader view of what "concurrent" means at first, talking about computers on a network or multiple programs on the same machine, but the Java specific discussions surround the more typical notions of concurrency.
The reading introduces two models for concurrent programs: shared memory and message passing. In the shared memory model, separate programs may share physical memory or even the same Java objects. Message passing is compared to networking or piped command line programs.
Our programs run inside a process, which the reading compares to a virtual computer running in it's own memory space, isolated from other programs. Within this process, we can have many threads of execution (Dave Crabbe explains the relationship of processes and threads in his YouTube video on the subject). Because there are a finite number of CPU's (or CPU cores, anyway), and many, many more threads, it is necessary to divide up the work, a process called "time slicing". With time slicing, the CPU will execute some instructions on one thread, switch to another, execute some instructions, and so on, in order to mimic multitasking.
The reading spends some time covering how to spin up new Threads and execute code in them, using anonymous classes implementing the Runnable interface. One tidbit of new information for me was the fact that if you call run() on the Thread (instead of start()), or call run() directly on the Runnable (instead of dropping it in a thread and calling start()), then that code will run synchronously on the thread from which it was called.
The reading also covers the concepts of interleaving and reording (also covered in the Google talk). Basically, the compiler and the CPU will often do things to optimize code that flies in the face of what we believe that code is supposed to do. While this won't bite us in single threaded applications, it can create subtle, hard to reproduce bugs (called heisenbugs) in concurrent code. Steps that would normally be helpful to debugging, like print() statements, can change the timing of the code in such ways as to make reproduction impossible.
While the Google talk covers some strategies for using locks and volatile declarations to combat some of the problems inherent with concurrent programming, the reading defers for now.
Week 10
This week is another easy one, just one reading, this time on thread safety. I found a course on Udemy covering Multithreading in Java that should serve as a nice companion to this and future lessons on concurrency in Java. I couldn't quite give it five stars because the intro music is so annoying, but the actual code examples were very informative.
The reading looks at three ways of making variable access safe in a multi-threaded application:
- Confinement - Local variables that are not exposed to multiple threads
- Immutability - Additional constraints are required to make immutable data thread safe
- Threadsafe data types - Existing types that can handle multiple threads
- *Synchronization - mentioned, but not expanded on (promised for a future reading)
Confinement takes the approach that there can be no race conditions due to shared mutable data... if there is no shared data. This basically boils down to ensuring that mutable data is local, making sure we aren't exposing object references, and definitely aren't using global variable.
Immutable data solves the race problem by tackling the other end... making the shared data immutable. This means declaring variables and references final, and making sure that immutable data truly never changes. It makes reference to the idea of beneficent mutation, where an immutable type makes internal mutations that are invisible to clients (like caching the size of a list). Even this kind of mutation can cause problems in concurrent apps. The other restrictions are what we would expect for an immutable type: no mutator methods, fields are private and final, and no rep exposure.
Certain types provided by Java are already thread safe. StringBuffer is a thread safe class for creating strings similar to StringBuilder (which is not thread safe). The java.util.collections includes static methods to create thread safe collections (Collections.synchronized<Map,Set,List>(<your collection>)). The java.util.concurrent also includes classes that are thread safe, such as ArrayBlockingQueue, which is demonstrated in part 7 of the Udemy course. The reading cautions again trying to circumvent the synchronized wrapper classes (well duh), so make sure you lose any references to the old collection after you've synchronized it.
We can make thread safety arguments in much the same fashion as we make comments on the rep invariants and abstraction functions (it actually puts the comments in the same block). Basically, a good thread safety argument will demonstrate that our code exhibits the qualities demonstrated above. Mutable fields are local, with no external object references. Public fields are final and point at immutable data types. Or shared data is encapsulated in a thread safe data type.
There are some tricky cases. The reading gives the example of a Graph class that represents the nodes and edges in two thread safe collections. While on the surface this may appear to help, if changes that affect both nodes and edges are not performed as an atomic operation (using synchronized blocks, for example), then there is still a risk of breaking the rep invariant and ending up in an invalid state.
The last concept covered in the reading is serializability. "Serializable", in this sense, is referring to the schedule of operations, and requires that the end result is a possible result of a sequential ordering of all the operations. This doesn't mean that the operations actually were sequential (which would make the whole concurrency thing moot), it just means that the result is consistent with such an ordering. The reading really glosses over this concept, and the Wikipedia article goes waaaaay off into the weeds... just can't win sometimes. Did find a short lecture on YouTube explaining the basic idea.
Week 11
Readings this week cover Sockets & Networking (reading 7), and Queues & Message Passing (reading 8). It was sort of a strange mix of material. Some of the concepts were really familiar (IP addresses, hostnames, ports, how clients and servers work generally), but there were still some aha moments, particularly with regard to how sockets work. I look forward to playing with the last pset, which has us building a client-server version of minesweeper. I found a lecture from nptel covering Client-Server Programming in Java, as well as a video demo working with sockets that focused strictly on the code, that complemented the reading material well.
Sockets in Java actually make network communication pretty transparent to the application. Once you've established the network connection, messages are written to and read from input and output streams, just like any other stream to and from a file or the console. There are two components required to make these connection possible:
Sockets in Java actually make network communication pretty transparent to the application. Once you've established the network connection, messages are written to and read from input and output streams, just like any other stream to and from a file or the console. There are two components required to make these connection possible:
- ServerSocket - listens on a given port for incoming requests
- Socket - given an IP or hostname, and a port, establishes connection with listening server.
These classes use TCP. The DatagramSocket can be used for UDP, which does not have the reliability guarantees of TCP but can be faster. SSL versions of Socket and ServerSocket also exist. The reading makes a point of emphasizing that calls to read() on the input streams is a blocking call when the buffer is empty, and symmetrically calls to write on the output stream are blocking when the buffer is full. The blocking section teases deadlock a bit, and a later example points out that two buffers can end up blocking forever waiting for the other to do something, but most of deadlock is covered the last week.
The "Wire Protocols" section of the reading was also fun, for the simple reason that it gave me an excuse to fire up telnet. It also tied back to the grammars portion of the course. I did not know that the http protocol is actually defined as a grammar in rfc2616. Mind blown. The last bit in reading 7 is some advise on testing, which basically says try to separate the networking bits as much as possible to keep everything else testable. It points out that if you structure your code right, you can substitute in-memory streams for network streams in your tests, making them much faster and more robust (done this before, recently too).
Reading 8 deals with message passing. While client-server is an obvious example, you can use message passing between threads on the same machine as well, using a shared, thread-safe mutable queue. The example they use is super similar to the example from the Udemy multithreading course. By using a shared BlockingQueue, we can implement the producer-consumer pattern. Producers may or may not block when calling put() to add items to the queue (depending on capacity constraints), and consumers will block on calls to take() when the queue is empty.
When we want a thread to stop, we need a strategy to do that in a clean way. While it is possible to send a thread an interrupt signal, if you are just catching all the exceptions in an infinite loop, you are out of luck. However, you can check if a thread has been interrupted with the Thread.interrupted() method (here Thread will reference the current thread). Another strategy is called a poison pill, where you use polymorphism to introduce a type into your queue that will halt the execution of a consumer gracefully when it encounters it.
The last point made in reading 8 is that it is important to really think hard about your thread safety justifications when using message passing as a concurrency strategy.
Week 12
The long anticipated (dreaded?) unit on locks and synchronization!
Synchronization is a tool for preventing multiple threads from accessing the same section of code at the same time. It can be an important part of solving problems involving race conditions. One way of approaching synchronization is through the use of locks (also seen it called a mutex). The canonical example of using locks is the bank account example. Because increment operations are not atomic (they consist of a read, an addition, and an assignment), multiple threads trying to modify the same data at the same time can result in an interleaving of these operations that corrupts the data. By requiring each thread to "acquire" the lock to a block of code before entering it, we can prevent such weaved operations, since only one thread will be modifying the variable at a time. This basically gives us little chunks of single threaded code within our concurrent code.
There are some tradeoffs involved in using locks. There is a performance impact, both from the operation of acquiring the lock, and because we are creating a bottleneck. This can be really bad if we aren't mindful of which object is actually acting as the lock. If two unrelated operations use the same lock, then any time one method holds the lock, the other can't execute. And of course there is the dreaded problem of deadlock.
Deadlock occurs when two processes or more processes are trapped in a kind of cyclic block, where each holds one of several locks they need, and are waiting to get a subsequent lock that is being held by the other processes involved in the deadlock. Dijkstra illustrated this problem quite well with his Dining philosophers problem. A simple example with two threads and two locks goes something like this:
The player commands are implemented using a Command pattern not unlike what I put together for gitlet. The board follows the State pattern, with the play field represented as a two dimensional array of abstract squares. The concrete types for the squares represent a mined or unmined, hidden or reavealed, with decorators for whether the space is flagged or unknown. The board and the squares use an event listening arrangement for updates related to revealing or exploding squares. It isn't perfect... there are areas that I feel are too tightly coupled, but it works at least.
Converting the single threaded game server to a concurrent server was as simple as wrapping the code that handles the incoming socket connection in it's own thread. The server maintains a copy of the board, which should be thread safe since the state changing methods are all synchronized.
[After final grader]
So I learned a bit about the way ant runs (or can run) JUnit tests. I had no problem running the tests from the grader task, but there was a lot of rumbling on the discussion board about binding errors and other wonkiness. Turns out if you copied the final tests out of the final grader jar and dropped them in your project so you could run them with JUnit from eclipse, everything went to hell. I tried it and spend probably a good hour dicking with it, trying to fiddle with my MinesweeperServer to make it work with these tests. It turns out it was really a futile effort form the beginning.
The reason it was futile is because the final grader tests were never designed to be run in sequence. Each test runs the server on the exact same port, on a new thread, and never closes it. Literally the only way they work is when you run them one at a time. So how does ant do this? Turns out it "forks" each test case onto it's own vm. So it's basically like running them one at a time in succession. Personally I think it's a serious weakness of the tests (they aren't isolated!), but whatever... my tests work fine =P


Synchronization is a tool for preventing multiple threads from accessing the same section of code at the same time. It can be an important part of solving problems involving race conditions. One way of approaching synchronization is through the use of locks (also seen it called a mutex). The canonical example of using locks is the bank account example. Because increment operations are not atomic (they consist of a read, an addition, and an assignment), multiple threads trying to modify the same data at the same time can result in an interleaving of these operations that corrupts the data. By requiring each thread to "acquire" the lock to a block of code before entering it, we can prevent such weaved operations, since only one thread will be modifying the variable at a time. This basically gives us little chunks of single threaded code within our concurrent code.
There are some tradeoffs involved in using locks. There is a performance impact, both from the operation of acquiring the lock, and because we are creating a bottleneck. This can be really bad if we aren't mindful of which object is actually acting as the lock. If two unrelated operations use the same lock, then any time one method holds the lock, the other can't execute. And of course there is the dreaded problem of deadlock.
Deadlock occurs when two processes or more processes are trapped in a kind of cyclic block, where each holds one of several locks they need, and are waiting to get a subsequent lock that is being held by the other processes involved in the deadlock. Dijkstra illustrated this problem quite well with his Dining philosophers problem. A simple example with two threads and two locks goes something like this:
- Threads 1 and 2 both need locks A and B
- Thread 1 acquires lock A
- Thread 2 acquires lock B
- Thread 1 is waiting for Thread 2 to release lock B
- Thread 2 is waiting for Thread 1 to release lock A
Both die of starvation.
One way around this form of deadlock is by carefully ordering how keys are aquired. In the above example, if keys are acquired in alphabetical order, then the first to get lock A will also get lock B, while the loser waits for both.
The reading covers a pattern for managing concurrent access called the monitor pattern (I'm not sure it means the same thing as the similarly named Wiki page). In this pattern, every method that touches the internal representation is synchronized. They have us decorating a bunch of methods with the synchronized keyword. I gotta say, I thought I've seen it said that doing this can tank your performance, so it gave me some pause. But I don't know, I haven't done much concurrent programming myself...
Well they do caution against over use of synchronization, apparently I just had to review a little farther. What I get for not taking notes...
Multiplayer Minesweeper
The last pset for the Advanced course (and also the last pset for the official course) is a multiplayer minesweeper game that is played using telnet. Honestly I thought this one was going to be a lot harder, but it was just challenging enough to be really fun. [Next day] Course I say I thought it would be harder and then today I spend half the damn day chasing down a weird bug. I guess I jinxed it lol.

The skeleton code has some pretty knarly command parsing code, which I blew away in favor of my own command parsing that uses the SimpleParser library and a factory pattern. I actually initially assumed that some grammar parsing was part of the assignment, but when I actually read through the entire MinesweeperServer class (after finishing the parsing code), I figured out they sort of included it already. But one thing I wanted to do with this assignment was create some really elegant, object oriented, polymorphic code.... and some of the included code was pretty far from that. 
The player commands are implemented using a Command pattern not unlike what I put together for gitlet. The board follows the State pattern, with the play field represented as a two dimensional array of abstract squares. The concrete types for the squares represent a mined or unmined, hidden or reavealed, with decorators for whether the space is flagged or unknown. The board and the squares use an event listening arrangement for updates related to revealing or exploding squares. It isn't perfect... there are areas that I feel are too tightly coupled, but it works at least.
Converting the single threaded game server to a concurrent server was as simple as wrapping the code that handles the incoming socket connection in it's own thread. The server maintains a copy of the board, which should be thread safe since the state changing methods are all synchronized.
[After final grader]
So I learned a bit about the way ant runs (or can run) JUnit tests. I had no problem running the tests from the grader task, but there was a lot of rumbling on the discussion board about binding errors and other wonkiness. Turns out if you copied the final tests out of the final grader jar and dropped them in your project so you could run them with JUnit from eclipse, everything went to hell. I tried it and spend probably a good hour dicking with it, trying to fiddle with my MinesweeperServer to make it work with these tests. It turns out it was really a futile effort form the beginning.
The reason it was futile is because the final grader tests were never designed to be run in sequence. Each test runs the server on the exact same port, on a new thread, and never closes it. Literally the only way they work is when you run them one at a time. So how does ant do this? Turns out it "forks" each test case onto it's own vm. So it's basically like running them one at a time in succession. Personally I think it's a serious weakness of the tests (they aren't isolated!), but whatever... my tests work fine =P
Final

No comments:
Post a Comment